









What’s new?
Stay up-to-date with our weekly release notes.

We've built SLA Alerts directly into Stories so teams can stay ahead of high-priority work with automatic deadlines, early breach warnings, and clear visibility when commitments are missed.
Check it out →
Improvements and Fixes
- Epics Kanban View to view across all of your Epic workflow states from backlog to shipped
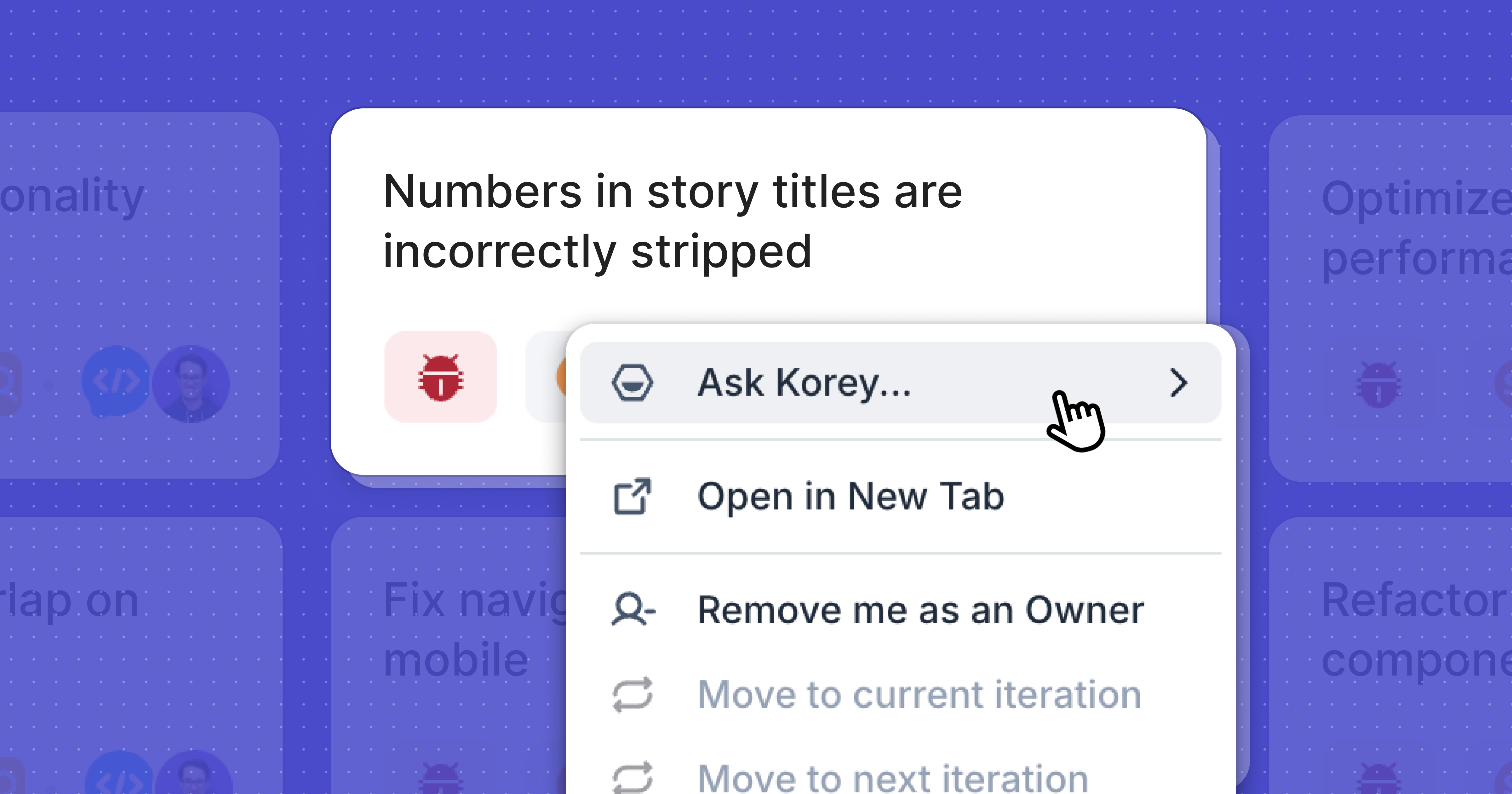
Access Korey from Shortcut's right-click context menu to refine Stories, Epics and Iterations without leaving your flow. Korey can improve descriptions, clean up acceptance criteria, generate Sub-tasks, spot dependencies and more.
Improvements and Fixes
- When assigning Epics to Stories, the Epic list in the selector now starts with recently viewed
- Right-clicking on related and blocking Stories now opens them in a new tab
- Resolved an issue where the top portion of the "+ Add Space" button became unclickable when a scrollbar was present
- Fixed an issue in Firefox on Linux where the Story description field didn't scroll with the mouse wheel
Story titles now support backtick formatting for inline code, just like descriptions and comments. It's now easier to distinguish technical terms from general topics at a glance. 🙌
Improvements and Fixes
- Strategic and Tactical Objectives now display distinct colors and icons in Roadmap view
- Reduced latency when filtering and interacting with the UI
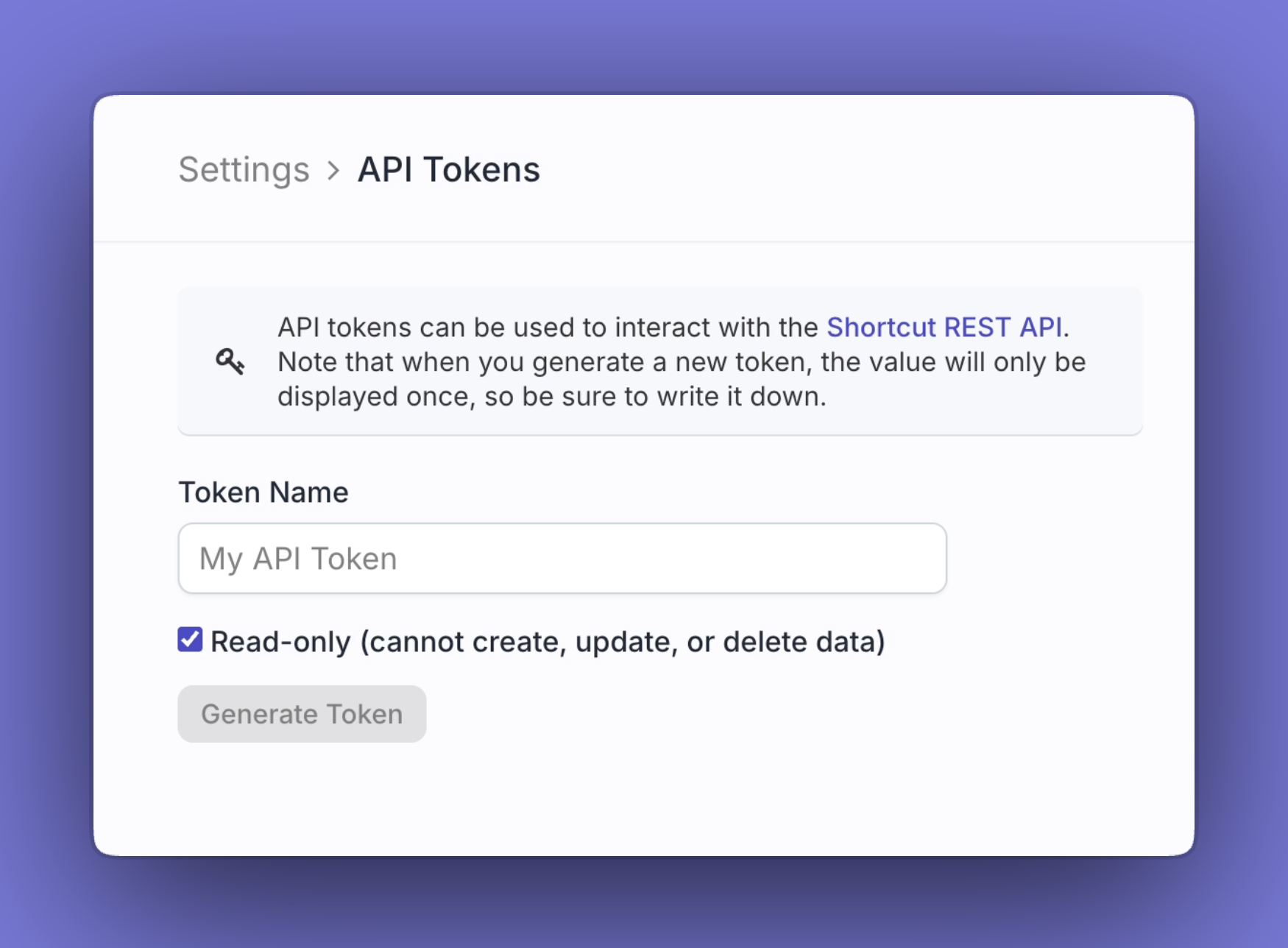
API tokens now support read-only and read/write access with scoped permissions.
New API cookbook recipes
We’ve published two new recipes in the API cookbook to help teams access commonly requested delivery data.
Improvements and Fixes
- Fixed story printing issues across Safari, Firefox, and Chrome
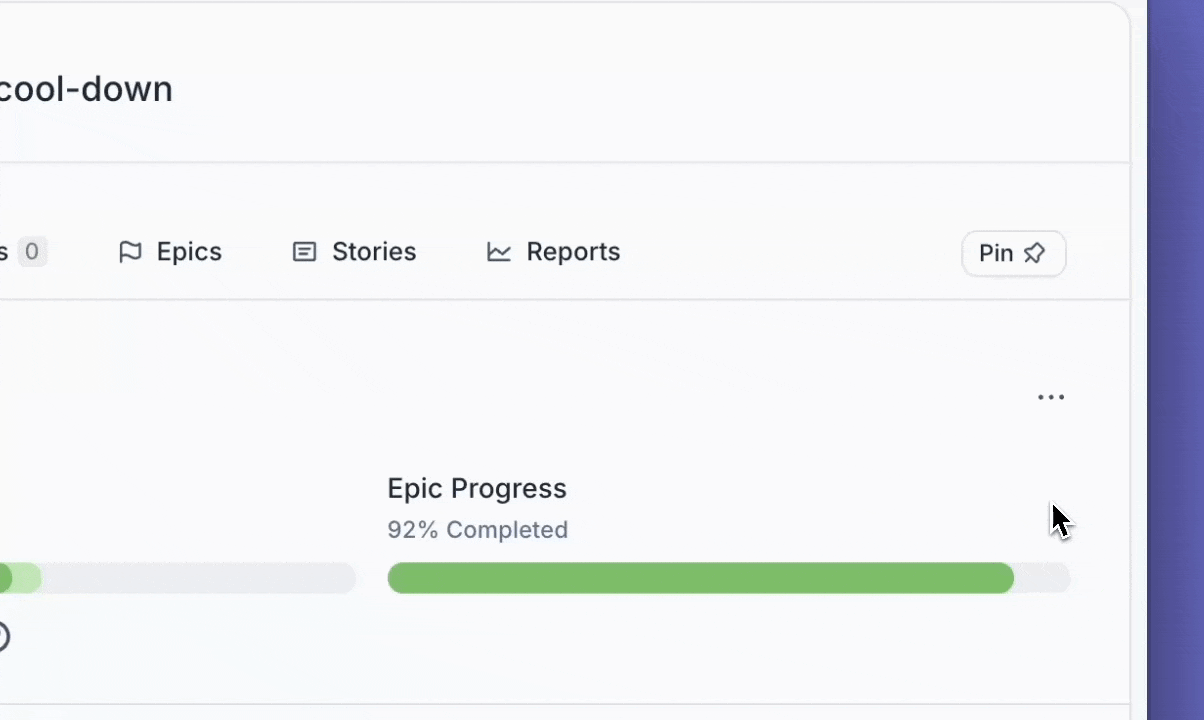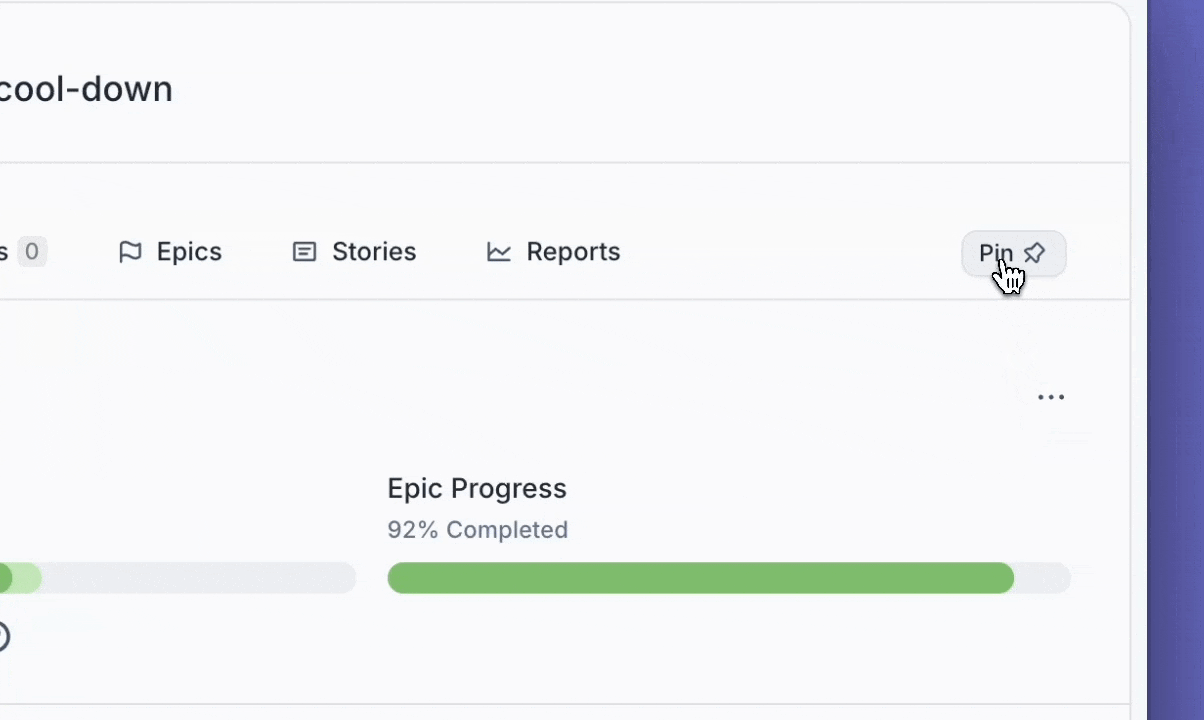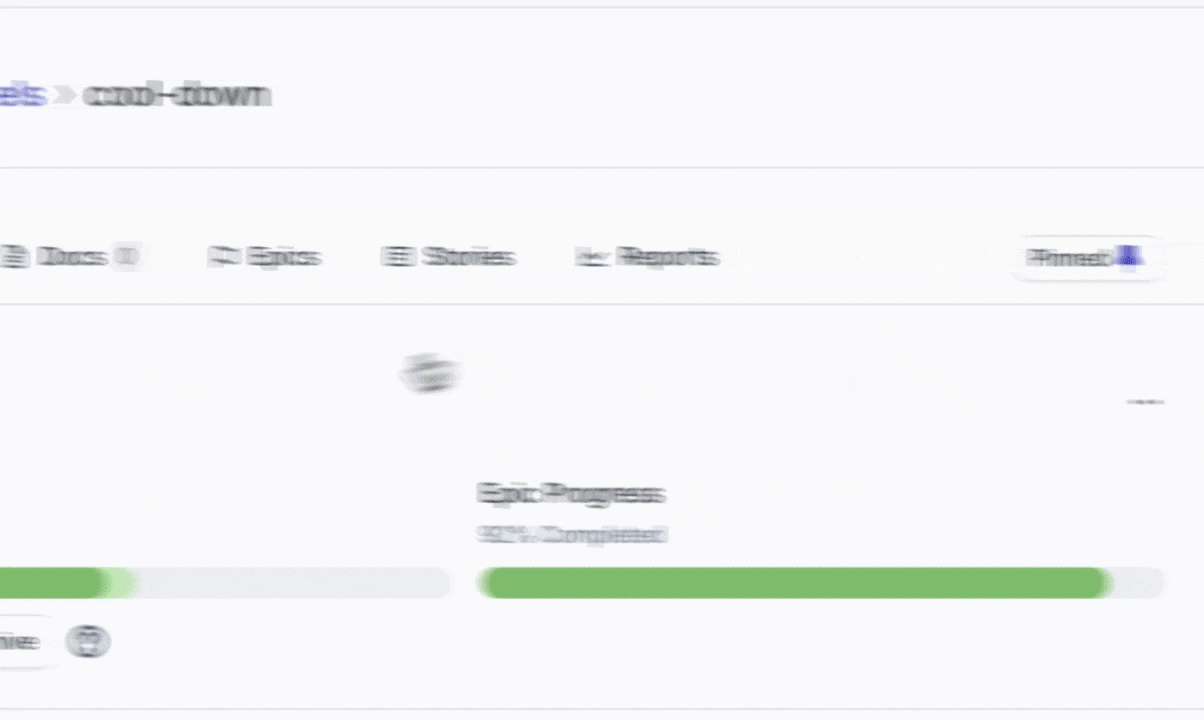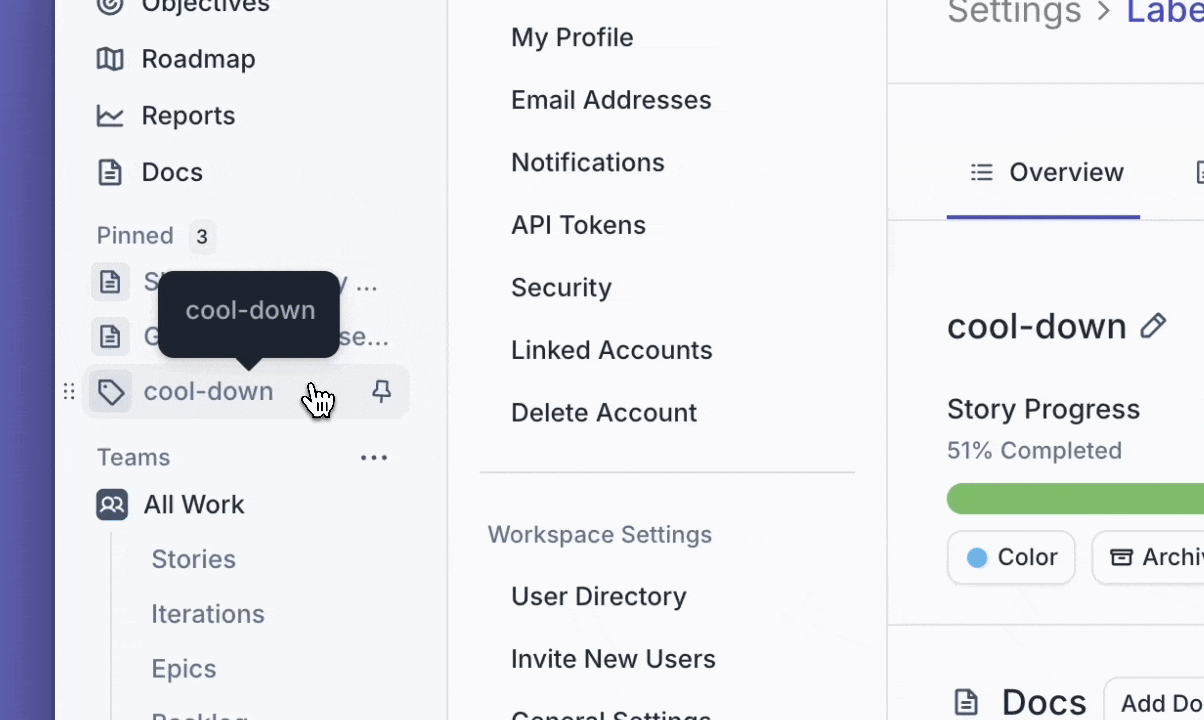
You can now pin Label pages to your left navigation so your most-used pages are always within reach.
Filter Label detail pages by Epics
It just got easier to focus on your work! You can now filter Label detail pages by Epics.
Improvements and Fixes
- Custom estimate scale values now properly validate to only accept whole numbers
- The "Create a Story" and "Create a Story from Template" Zapier actions now support creating Sub-tasks, enabling full automation of Story creation with associated Sub-tasks
- Story content now displays correctly when printing to PDF in Safari
- Label dropdowns in the Story dialog no longer overflow beyond the viewport
- Dropdown arrow icons in Roadmap filter controls are now fully clickable
- Objective Type info tooltips now have proper contrast and visibility in Light Mode
- Dark Mode UI tweaks and other small UX bug fixes
You’ll now get a Slack notification when someone @-mentions you in a checklist item, helping you stay aware of updates as they happen. ⚡️
Pin Spaces
Pin Spaces you use frequently so they stay visible in your workspace.
Improvements and Fixes
- Fixed dark mode toast notifications appearing in light mode for @-mentions
- Improved command bar functionality (⌘K) with label updates, owner updates, and "Go to Space" shortcut
- Addressed 15+ visual and styling bugs, including button alignment, icon sizing, and color consistency
- Updated integration logos for dark mode compatibility
MCP Server
- You can now create, add, and remove Sub-tasks using the MCP Server
We’ve migrated to a new, native ⌘K shortcut system. All existing shortcuts are supported, and you can customize your own in the new system.
Improvements and Fixes
- Corrected a bug where inviting new users from the Followers menu didn't work.
- Improved light mode toasts so link text is now clearly visible.
- 🤖 Bot-owned Stories no longer get the team membership warning “!” indicator, since bots don't need to be on a specific team.
- SVGs now render correctly in Stories, so attached diagrams and graphics show up inline instead of as broken images.
- Corrected an issue with an incorrect Keyboard Shortcut Action.
Checklist items now appear right after you add them, so you can keep moving without losing your place. 🙌
- Task lists in the markdown editor no longer show bullets, making them easier to scan and read.
- Fixed an issue where choosing an emoji in a checklist would close the input.
- Corrected a layout bug where navigation arrows disappeared in expanded Story view on 13" screens.
- Story links missing a workspace in the URL no longer open to a blank page.
- Updated the color contrast on Key Result hover text so it’s readable again.
- Objective cards no longer flicker when scrolling on mobile Safari.
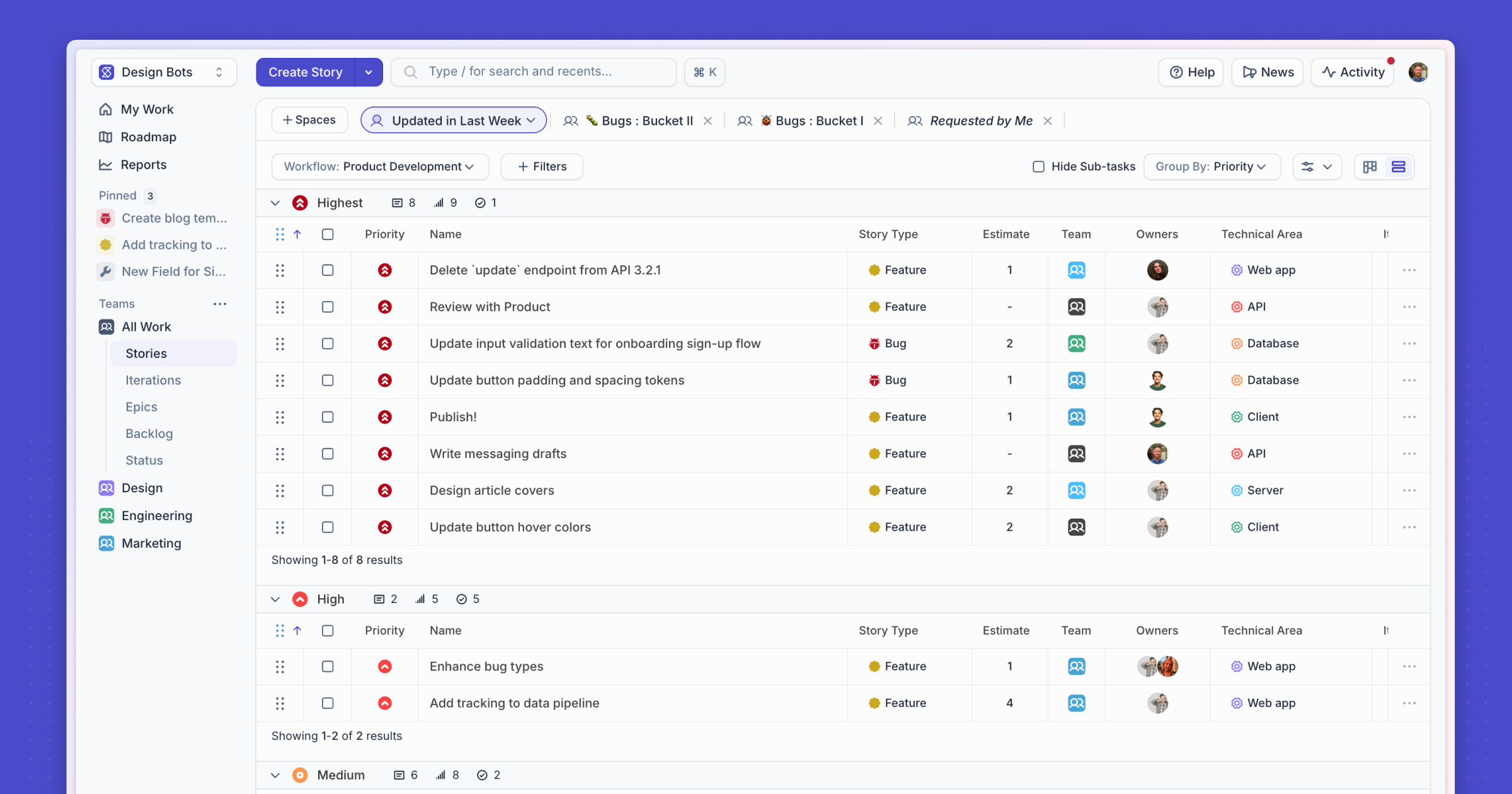
Shortcut now has a new, modern interface designed to make it easier to focus on your work. You’ll notice updated fonts, colors, and icons across the app, creating a cleaner, faster, and more consistent experience between Shortcut and Korey. Read more about what's new →
New Integrations
Create Stories from Fireflies meeting tasks
Turn your meeting action items into Shortcut Stories — instantly, so every task moves forward. With the integration, you can:
- Automatically create Stories from meeting tasks
- Create Stories just for your tasks or for every meeting task
- Add routing rules so Stories land with the right teams
Automate your workflows with the IFTTT Integration
Connect Shortcut to 1,000+ apps and let routine tasks run themselves. With customizable triggers and actions, you can keep work moving without manual updates. With IFTTT, you can:
- Get Slack notifications when you're assigned a Story
- Turn Google Forms responses or Discord messages into Stories
- Create calendar events (iOS, Microsoft, or Google) for new Stories and Epics
Improvements and Fixes
- You can now copy your API token to the clipboard with a single click
- Copy Epic names from right-click menu on Roadmap views
- Fixed a bug that prevented the API key from being visible
- Corrected the “Go to” button text in Epics table view so it now points to the right place
We’ve made more updates to the new UI in Early Access, including improved dark mode and refreshed icons.
Improvements and Fixes
- Resolved an issue where Parent Story names flickered in group headers when stories were updated.
- Corrected a bug that caused deleted Sub-tasks to still appear when archived.
- Updated the Roadmap timeline view so new workspaces with Objectives turned off will see “Add Epic” instead of “Add Objective.”
Opt in to try our refreshed UI featuring updated fonts, colors, and icons across the app. We'd love to hear any feedback you have about the new experience.

Improvements and Fixes
- Custom Fields are now properly updating with Sub-tasks
- Fixed the user dropdown filter so it no longer includes the current user.
- Cleaned up minor visual issues in roadmap headers.
- Corrected an issue in the bulk editor that caused incorrect team values.
Improvements and Fixes
- Checklist items now save automatically when you click outside or close the Story.
- Selecting an emoji for a checklist item no longer closes the text box.

Work faster with an AI teammate who writes specs, tracks progress, and keeps your team moving.
- From idea to spec, instantly: Create a dev-ready Story with complete details, Sub-tasks, owners, and acceptance criteria.
- Instant release notes and status: Get quick summaries of work to share during stand-ups or to understand what shipped.
- Context across your projects: Korey pulls context from across your development workflows and keeps everything in sync. Connect Korey with Shortcut and GitHub Issues today, with more connectors coming soon.
- And more: Explore our prompt library to see all the ways Korey can help.
Improvements and Fixes
- Fixed an issue where @mentions wouldn’t work in checklist items if they followed a code block.
- Sub-task CSV exports now include parent story fields for added context.
Get notified when you’re needed! You’ll now receive an email whenever a teammate @-mentions you in a checklist, making it easier to stay on top of detailed steps and shared to-dos.
Improvements and Fixes
- Parent Story headers now show the right state icon when you group by Parent Story.
- Activity Feed panel now stays open when you open and close a Story.
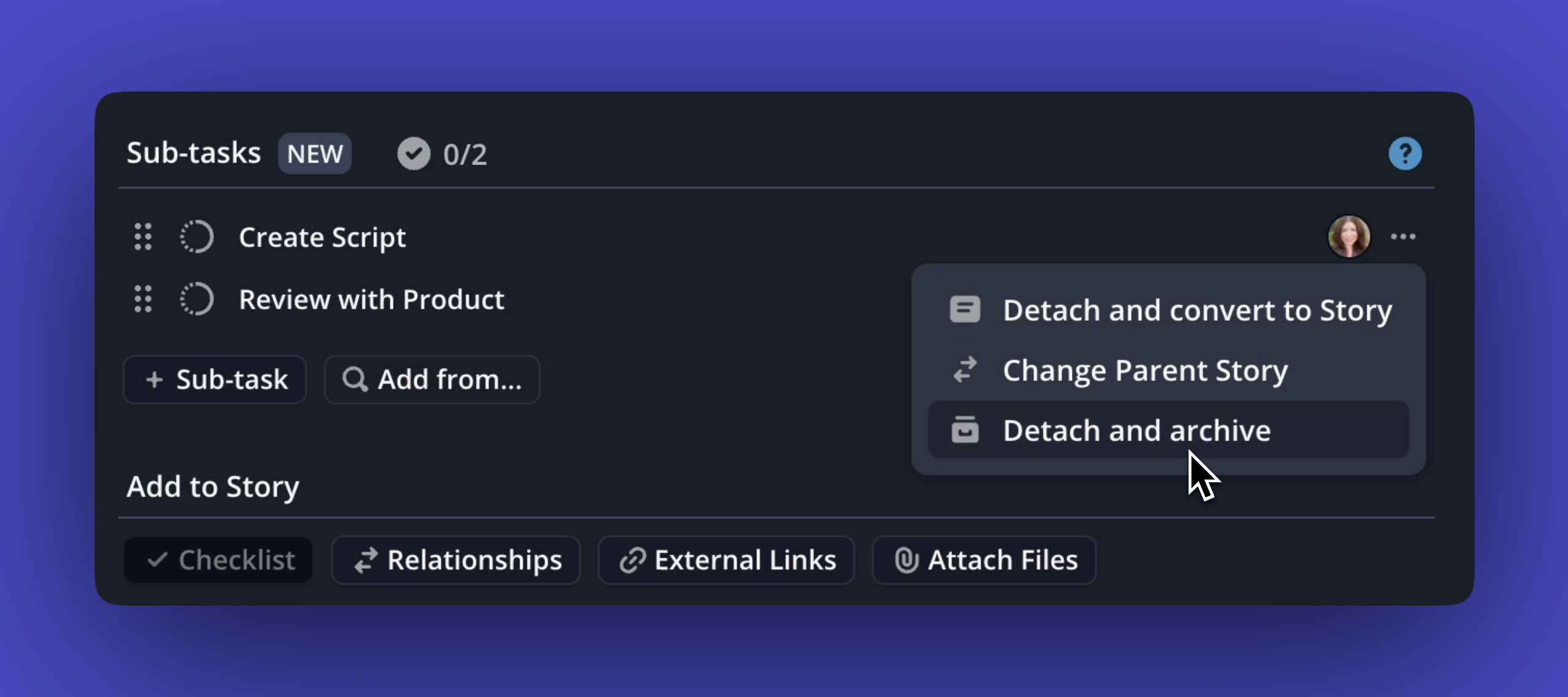
- You can now detach and archive Sub-tasks directly from the Parent Story’s three-dot menu.

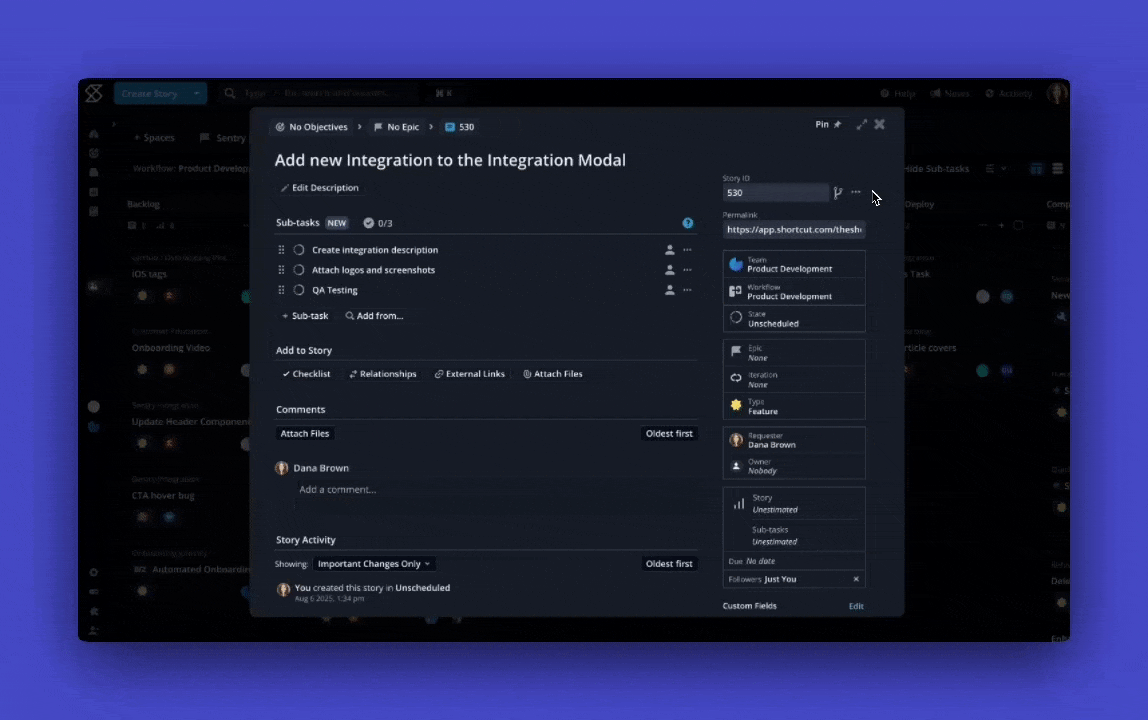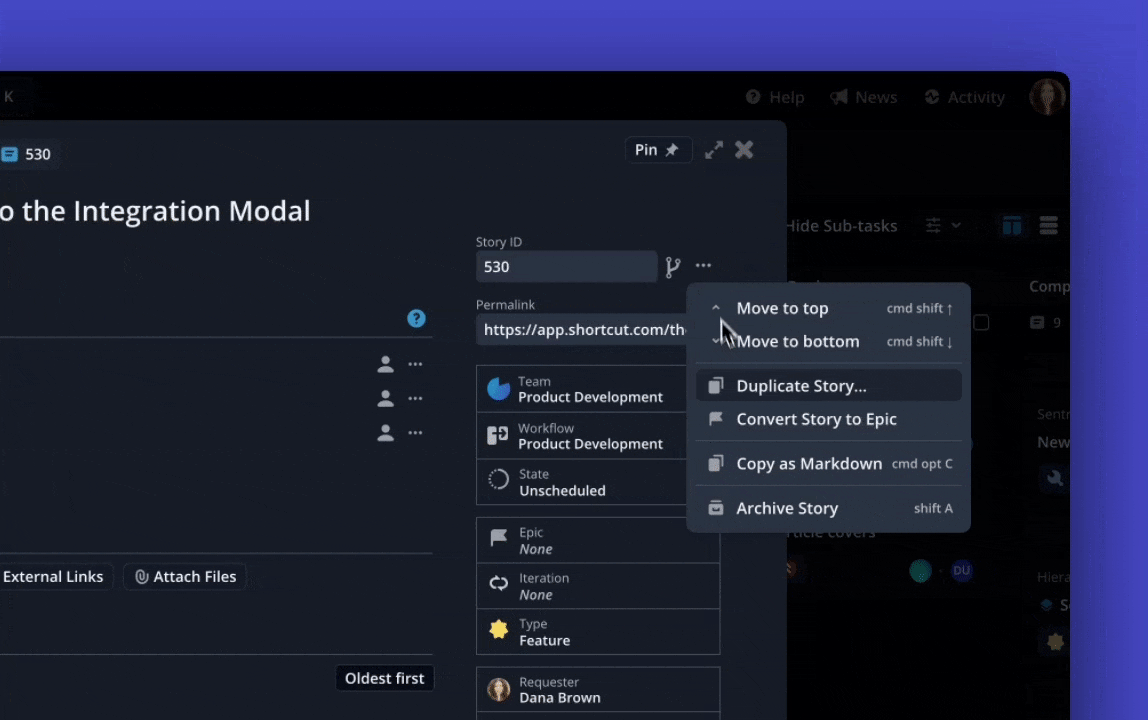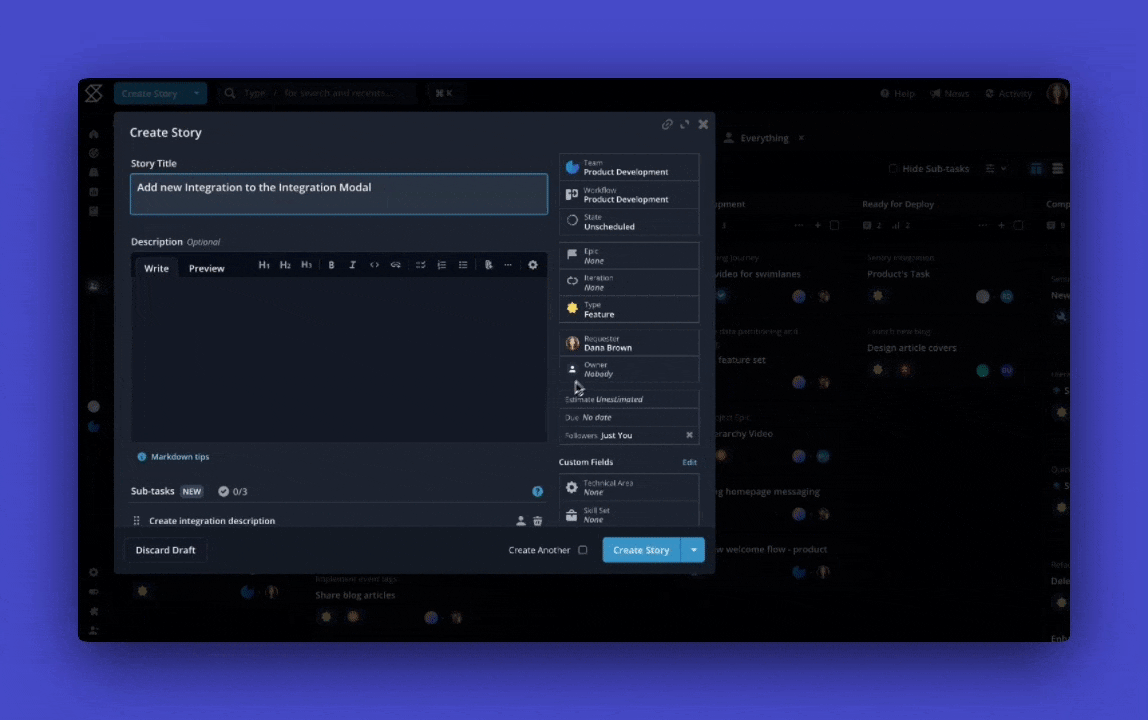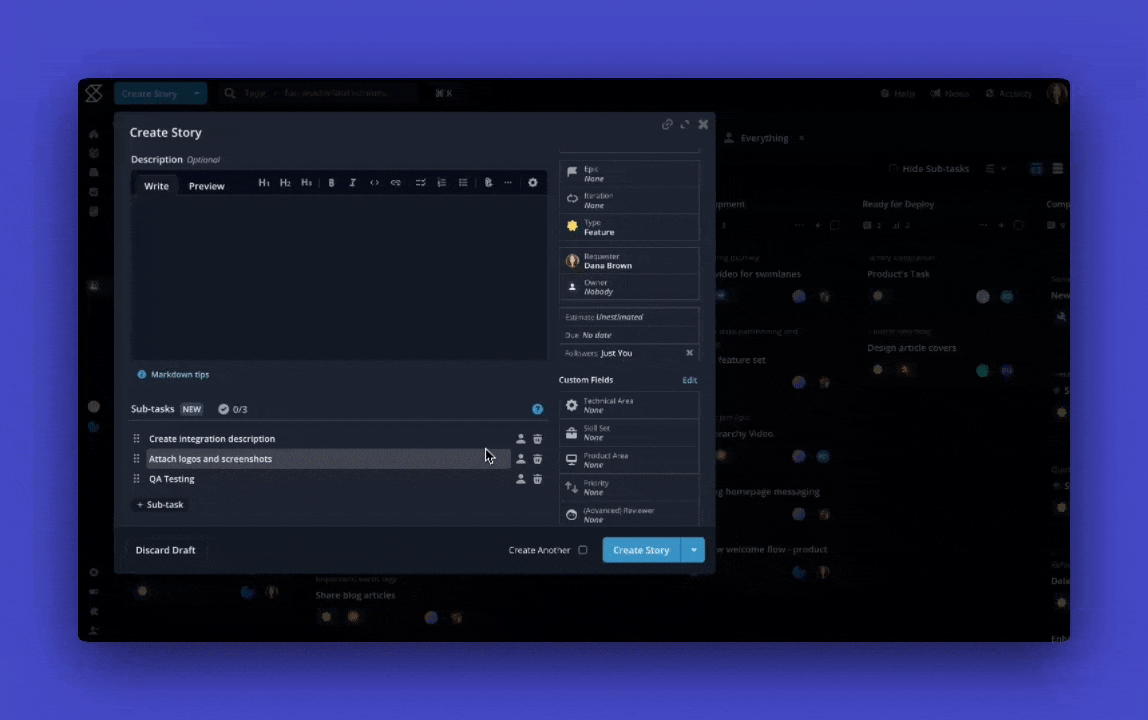
Sometimes the hardest part of shipping isn’t doing the work, it’s knowing exactly what the work is. That’s where Sub-tasks come in. Break any Story into small, actionable steps that keep projects moving forward.
- Create Sub-tasks directly in a Story, via the API, or automatically with Korey
- Estimate, connect to GitHub, and track through your workflow
- Use Automations so Sub-task progress can move parent Stories forward
👉 Enable Sub-tasks in your workspace via the Features page.
Improvements and Fixes
- Corrected a bug with Checklist Enter key behavior.
- Resolved an issue that caused the Checklist input box to close unexpectedly when clicked.
- Git Helpers now work properly with Sub-tasks.
- You can now toggle the Checklist section in My Work to show all items or only those where you’re @-mentioned.
- Legacy task owners now appear in checklist items as read-only, so historical data stays visible.
- Convert a Story into a Sub-task directly from its dialog using Add as Sub-task to… and select a parent Story.
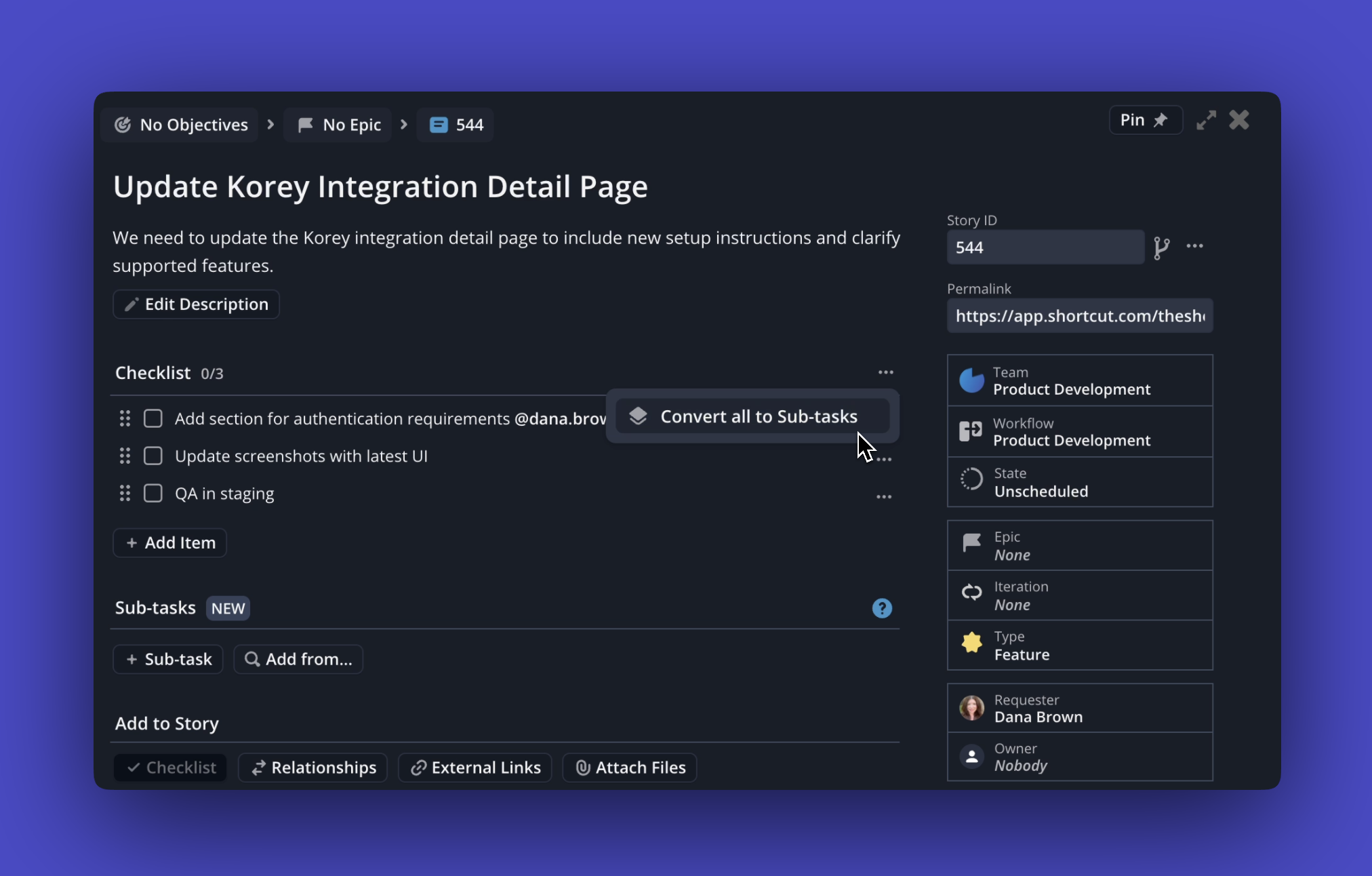
Sometimes a checklist starts small and then grows into a full set of real tasks. Now you can convert the entire list at once.
Open the three-dot menu in your Checklist and choose Convert All to Sub-tasks. Every item instantly becomes a Sub-task, ready to assign, track, and complete like any other.
This makes it simple to start lightweight and then scale up when your work needs more structure. No more converting items one by one. Just one click and you’re set.
Improvements and Fixes
- Multi-line checklist items now align the first line with the checkbox for a cleaner, more consistent look.
- Completed checklist items now always appear under Stories, even if no incomplete items remain.
- The Stories page filter for “Today” now correctly reflects updates made within the current day.
Keep track of quick to-dos right inside your Stories. Use them for personal notes or lightweight tasks, complete with Markdown and @-mentions for added context.
Tasks are now Checklists: Existing Tasks have been converted into checklist items. They still appear in Stories and are also visible on your My Work page.

API Updates for Sub-tasks
We’ve added a new API endpoint that lets you pull a list of Sub-tasks directly, without needing to query the Parent Story first. See our API documentation for full details for Sub-tasks.
Improvements and Fixes
- Fixed Firefox-specific editing issues in text areas
- Corrected an issue with extra slashes showing in PR Action Story Activity
- Tooltip text now appears correctly on the last column header in the Stories table view
MCP Server
Read-Only Mode: Set the SHORTCUT_READONLY environment variable to true to start the MCP server in read-only mode. In this mode, all tools that modify Shortcut data are disabled.
Archived entities are no longer included in search by default, keeping your results focused on active work. To include archived items when you need them, just add the is:archived search operator.
Search Stories with our new Search Operators:
- Iteration - Search for Stories in a specific iteration
- External URL - Search for Stories linked to a specific URL
- External ID - Search for Stories imported from external systems (like GitHub and others)
Pair any of these operators with has to return all Stories with (or without) that operator.
Improvements and Fixes
⚡ Zapier Integration: Added a new “Create Story from Template” action, making it easy to generate Shortcut Stories directly from your saved templates.
MCP Server
Upload files to Stories: Attach files directly through the MCP Server. For example, upload a UX image and your LLM can generate a Story that includes both the work and the image.
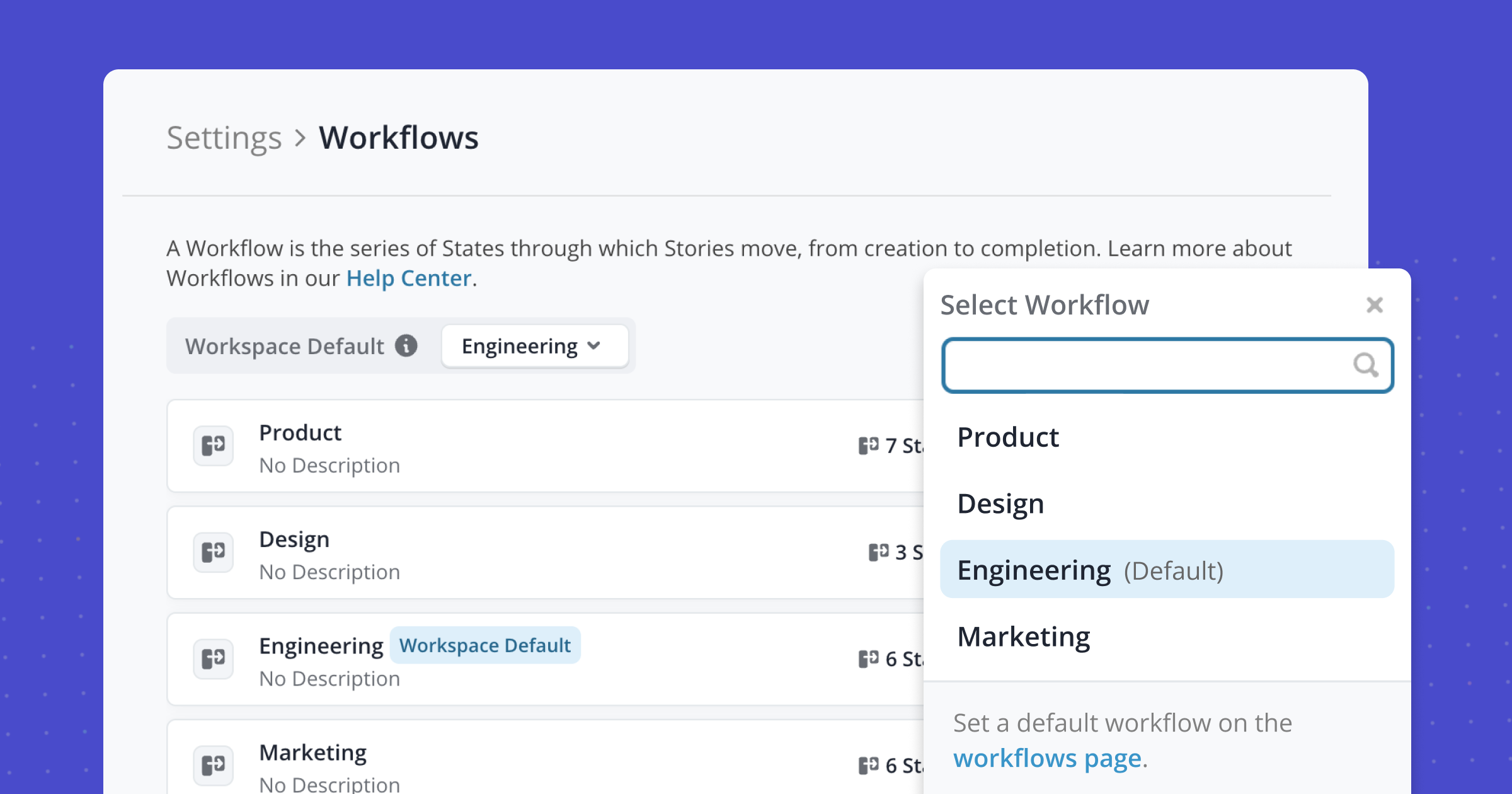
Creating Stories just got even smoother! You can now define default workflows, so Stories start in the right place, keeping work consistent and saving steps.
Improvements and Fixes
- API Docs Update: In our REST API, the endpoint previously called "Search Stories (Old)" has been renamed to "Query Stories."
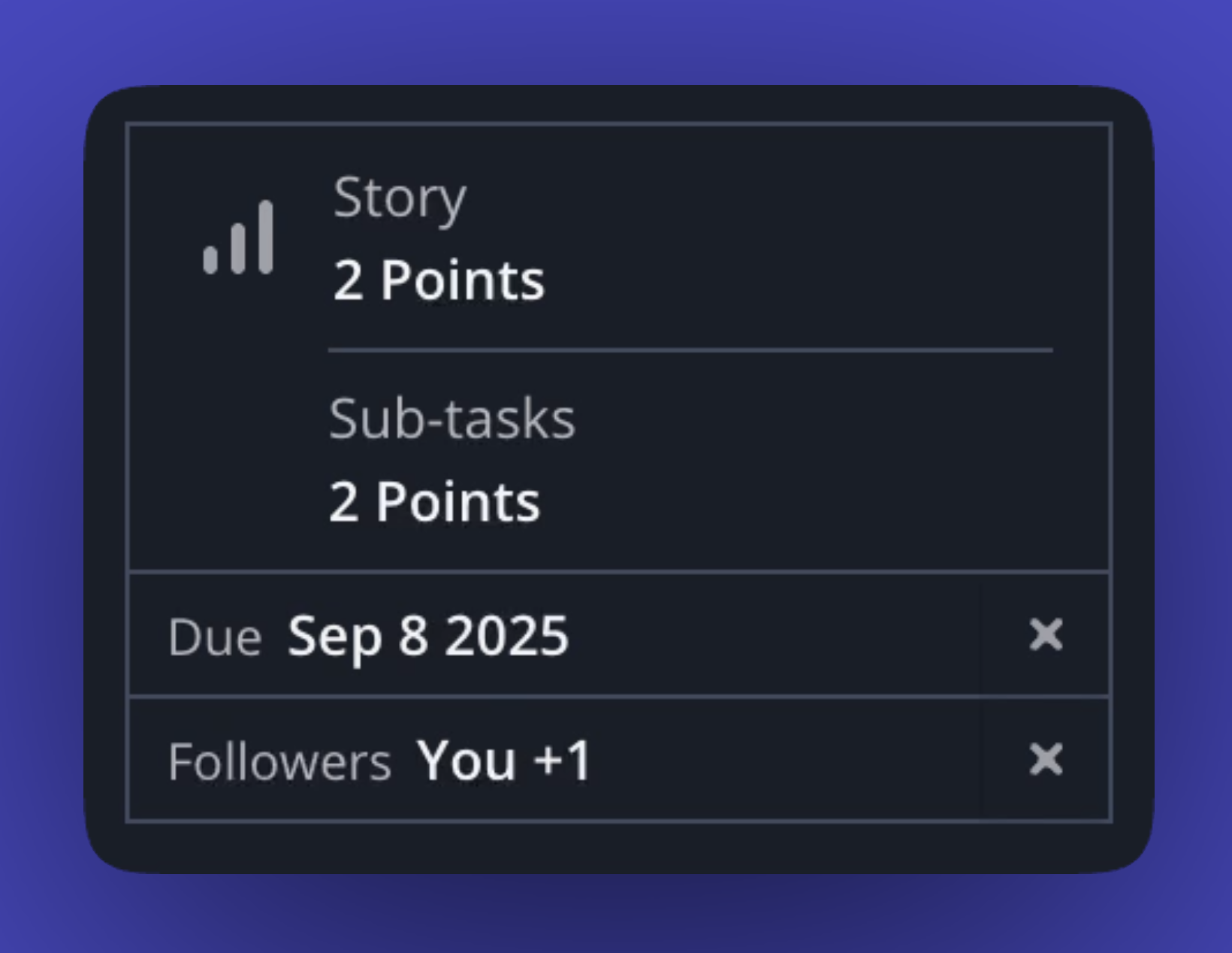
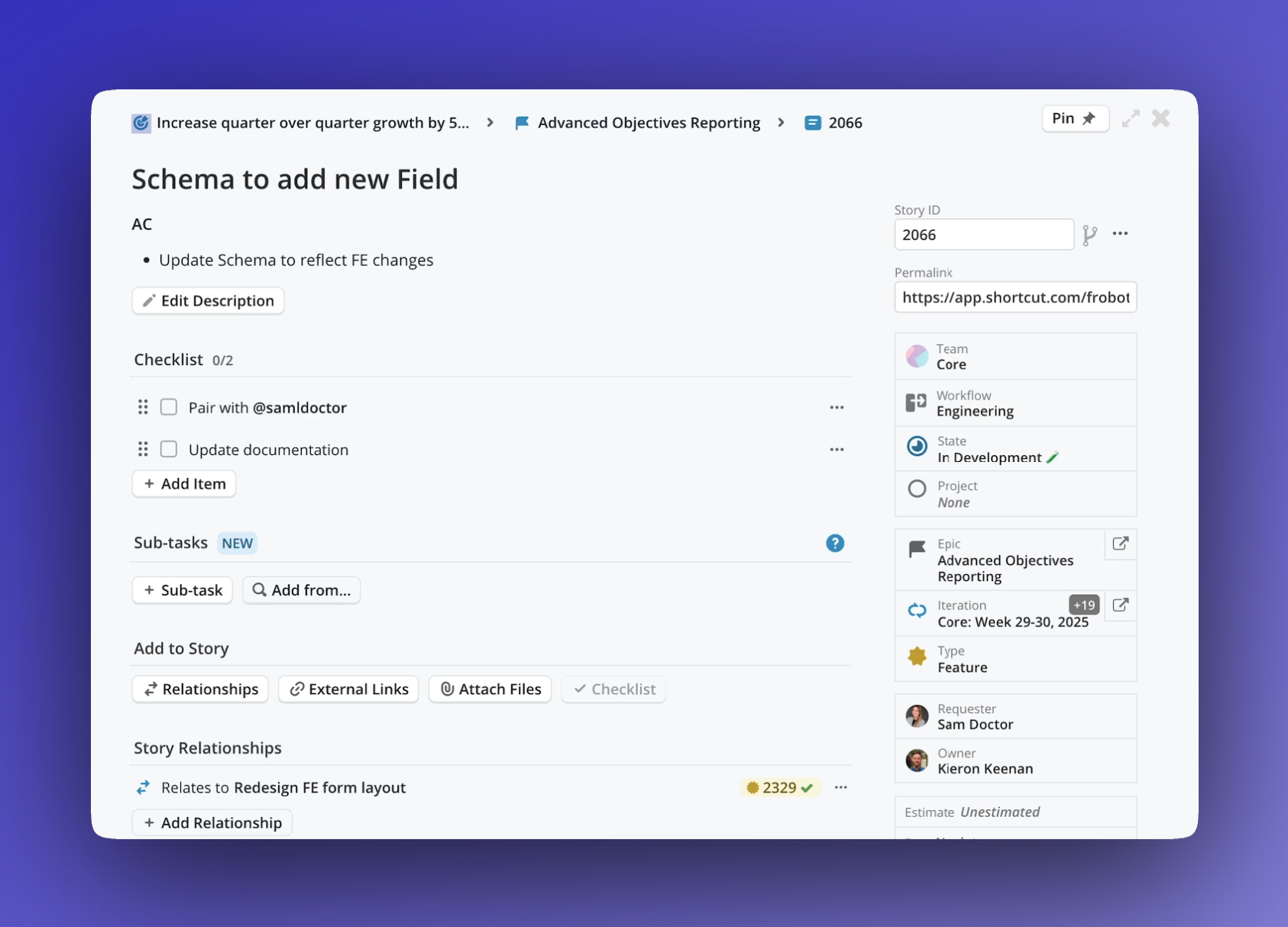
Quickly see the full scope of work by viewing the total points from all Sub-tasks right in the parent Story dialog.
MCP Server
- Pagination for search results – View and navigate results page by page so you can quickly find what you’re looking for.
- Slim responses by default – Saves tokens by returning only essential entity data, with the option to request the full API response when needed.
When duplicating a Story, any associated Sub-tasks will now be duplicated too. Whether you're reusing a detailed Story or building from a template, the full structure comes with it, so you don’t lose context or have to recreate work.
This only applies if you have Sub-tasks enabled. Join Early Access to start using Sub-tasks.
You can now see the total Sub-task points directly on the parent Story Card in Kanban View, so it’s easier to get a quick read on overall effort without opening each Story.
Coming Soon: You’ll also be able to view the total Sub-task points inside the parent Story, giving you a clearer picture of work scope wherever you're working.
New in the Korey Beta
- Writing Style: Korey now learns how you structure your Stories. Provide 3 writing examples, and watch Korey start crafting Stories that match your format. Markdown formatting encouraged. Set up your style in Settings > Writing Style
- Documentation: Korey Help Articles are now available
- Terminal Theme: Use ⌘ K to view and change themes, choose from light/dark or 🆕 Terminal
We're starting to move folks off the waitlist every day. Ready to meet your new favorite teammate? Join the Korey waitlist →
Improvements and Fixes
- We fixed a bug that affected the visibility of some optional workspace features
Parent Stories can now start or complete automatically based on their Sub-tasks. Set it up on the Automations page in Settings.
Now in Early Access: Checklists
Add checklists to Stories for quick personal tracking and lightweight to-dos. They support Markdown and @-mentions, making them great for jotting things down without assigning work. Checklists are available to teams in the Sub-tasks Early Access program.
Improvements and Fixes
- Addressed a card display bug on the Status Page
MCP Server
- The Shortcut MCP Server now supports creating Docs. For more details, read the blog post.
- Fixed an issue where Stories could be marked "Done" if pull requests with the same branch name existed in different GitHub repos
- You can no longer duplicate Docs with active suggestions to keep things tidy while the team’s still chiming in
- Fixed an issue where the workspace icon upload form wasn't responding. File selection and drag-and-drop now work as expected!
Find your next iteration quicker! We've updated the sort order in the Iteration dropdown in Stories, so your team's next iteration is at the top of the list.
Improvements and Fixes
Last week was Bug Bash week at Shortcut and we focused on fixes and papercuts to improve the everyday experience of using Shortcut. Here’s what we tackled:
- We tightened the spacing for nested bullet points in Markdown. Story descriptions look a lot cleaner now. 🙌
- Easier drag-and-drop to collapsed columns: The drop zone now includes the column title, so it’s easier to drag items where you want, even when things are collapsed
- Creating a new Story from the Relationships popover now opens the dialog in the right place
- Emojis now appear in email notifications: If your Story titles include a little flair (like 🐛 or ✅), they now show up correctly in emails
- You can now scroll the
Group Byfilter dropdown in the Backlog to see all options, regardless of viewport height - Cleaned-up URL previews: For dynamic Spaces, the hover tooltip shows a cleaner URL with no extra icons or messy formatting
- Long code blocks in Story descriptions now scroll properly
- We corrected the alignment on selected dropdown items with long text
- You can now Command+click or right-click on Settings and Integration links to open them in a new tab
- Story type icon colors now show up properly during import and mapping
- Integration icons now display correctly in dark mode
Break work into smaller pieces your team can tackle in parallel while staying connected to the bigger picture.

Use Sub-tasks to:
- Split implementation steps across teammates
- Track progress at a more granular level
- Keep everything synced across your workflow and GitHub
Sub-tasks are part of your Stories and move through your team’s workflow just like any other piece of work. Sub-tasks are now available by default for new Shortcut workspaces. If you're an existing customer and want to explore Sub-tasks, join Early Access here.
Improvements and Fixes
- Create and list Docs via API – You can now programmatically manage your Docs through our API endpoints, read more in our API Documentation.
- Connection Status – We added a notification for when Shortcut loses server connection so you know if updates aren't coming through.
Shortcut is now compliant with HIPAA. For more information and to request a BAA (Business and Enterprise plans only) visit our HIPAA Guide.
Improvements and Fixes
- You can now access our API documentation in OpenAPI format, making it easier to explore, understand, and connect to your apps
- Fixed an issue where the Labels dropdown was partially hidden when opened at the bottom of the Story Dialog
- Corrected a bug where the Severity 0 icon was not displaying in the Story and Backlog table views
- Stories no longer remain selected in Bulk Edit after being archived
- Fixed field assignment issues when creating a Story directly within a column in Kanban view

With Sub-tasks, you can break down user Stories into pieces of work for your team to execute on. Estimate, connect to GitHub, and move Sub-tasks across your team's workflow.
- Break down complex Stories into manageable pieces
- Track progress on individual components across your team's workflow
- Collaborate and break down work more effectively with your team
Improvements and Fixes
- When searching for a teammate using @mention, you can now use the up arrow to start from the bottom of the list of matches and loop back around, making it easier to find the right person when many names start the same
- Corrected an issue with Health Status UI groupings on the Objective page
Now it's easier to focus on what’s coming up. You can filter by Next Iteration to quickly see the stories your team’s about to tackle.

If you're planning, assigning or just trying to stay one step ahead, you can now:
- View Stories in the next iteration across your team
- Filter by owner or team within that next iteration
- Stack it with other filters to drill into exactly what matters
New Keyboard Shortcut
Copy any open Story and all of its context to Markdown with cmd/ctrl + opt + c

Improvements and Fixes
- Fixed a loading animation bug in the activity feed
It’s now easier to scan, navigate, and edit your workflows. Move faster and stay focused with a cleaner layout and quicker access to editing workflow states and WIP limits.

Create development-ready work in seconds with Korey
Spend less time writing up tasks and more time building. Meet Korey, your project management AI agent:
- Writes dev-ready stories and breaks down the work for your team
- Adds context and clear acceptance criteria to story descriptions
- Assigns work to human + AI teammates
- Provides status updates about your work
Improvements and Fixes
- Clicking an emoji suggestion in the description field no longer sends you to the bottom of the Story Dialog
- Navigation on team-scope pages now lands on the correct set of Space tabs
- Corrected a bug causing incorrect numbering and indentation in markdown lists
The way we build software is changing. AI isn’t just a feature anymore, it’s a teammate. Now, you can work side-by-side with agents directly inside Shortcut.
Introducing Shortcut for Agents
Assign your agents Stories just like you would any engineer. They’ll scope the work, write code, update docs, and move things forward, right alongside your team. Agents pick up the repetitive stuff, help close out your growing backlog, and leave the tricky edge cases to your humans. Learn more about Shortcut for Agents →

Introducing Korey
No one likes writing up tasks. So we built something that does it for you. Korey is a project management agent that creates development-ready work in seconds, translating ideas and notes into complete Stories in Shortcut.
Korey can:
- Create development-ready Stories and break down the work for your team
- Improve Stories with full context, transforming fuzzy details into clear acceptance criteria
- Assign the work to your human and AI teammates in Shortcut
- Provide real time status updates on what's done and what's next
New: Group by Workflow
Now you can group Stories by Workflow on Epic and Iteration detail pages, making it easier to get a real-time sense of where things stand.
Improvements and Fixes
- Epic Health updates are now available in our API
- Fixed a bug with team-scoped Stories Page URLs
- Corrected some behavior with bulk archive/deleting Stories
- Labels on a Story are now sorted in alphabetical order when viewed in Tables
Blocked and blocking Stories in the Backlog are now included in relationships shown on Story Cards, in Tables, and in Mermaid diagrams so you can see how work connects before it starts.
Improvements and Fixes
- Fixed an error toast that popped up when opening a Story dialog from an external link
- Corrected an issue that caused inconsistent Report visibility across Workspace Admins

Stories often have multiple implementation steps, and soon you'll be able to break them down with Sub-Tasks.
Capture the work that goes into a Story by creating individual Sub-Tasks that can be assigned to different team members and move across your team's workflow independently. This means clearer planning, better tracking, and more work moving to Done!
Manage and Track Work on the Stories Page
Watch our new video to see the Stories page in action. Create Spaces, apply filters, set WIP limits to keep work moving, and more.
Improvements and Fixes
- You can now add Stories directly from Kanban columns for Epic view Spaces using the "+" and “Add a Story” buttons

"View on Stories Page" from any Epic detail page by clicking the button at the top of the Stories table, or the magnifying glass icon in the left panel.
The New Stories Page is here for everyone
Everyone’s now on the new Stories page: enjoy faster load times, improved filters, and WIP limits. The legacy Stories page has been retired.
Shortcut.com has a new look

Shortcut has a new website! We updated our brand to reflect what makes Shortcut great: fast, intuitive, and enjoyable to use.
Improvements and Fixes
- We've added 10 new integrations, including: Plain, Guru, Aikido Security, Feedbucket, Make, Pipedream, Savio, Spike.sh, SureTriggers, Vanta and Zoho Cliq
- Clicking the Profile icon on the Email Settings page now works as expected
- Fixed a ghost toast! Editing then deleting a comment no longer haunts you with a “Your edits have not been lost” message
- Updating a Space name no longer triggers a warning when there’s nothing unsaved
- Pasting bullet points with asterisks now automatically removes duplicates asterisks to prevent formatting issues
- Images are now correctly inserted into the description content area rather than being added as attachments
We've released the first version of the open source Shortcut MCP server. Connect Shortcut to Cursor, Windsurf, Claude Code, and more. You can access and edit Stories and Epics in the apps to get your agents started coding and to connect the output directly to Github.
This is an early release that we plan to continue expanding. Bug reports and pull requests are welcome.
Faster List Editing in Markdown

We’ve improved the Markdown editor to help you move faster when creating and rearranging lists.
Here’s what’s new:
- Use
alt/option + ↑↓to move list items around - When copying a list item and pasting it into another list, we remove the automatically inserted bullet if the pasted content already contains a bullet
Improvements and Fixes
- Corrected a UI bug on the drop-down component of the Stories Page
- You’ll now see the provider and username when someone’s identity isn’t linked to Shortcut. No more mystery “somebody” making changes!
- Improved consistency when opening a new internal vs. external link
- Corrected a filter pill de-selection UI bug

See which Spaces are already in your Tab list when you open the "+Spaces" menu
Improvements and Fixes
- Improved filter logic for filtering workflow states on Spaces
- Only Save & Share changes to your Space when you need to. If you manually remove changes to your Space, the Space will revert to a "Saved" state 🙌
- Corrected a page load UI bug fix on table view when a story card is opened
- Updated the text on the Stories Page CSV export to include information related to Objectives
- Fixed a UI bug on the Cumulative Flow Diagram
You can now quickly copy Epic titles by right-clicking in our updated tables, including the Stories Page, making it easier to grab what you need and keep moving.
Improvements and Fixes
- Stories under "All Work" now load faster.
- No more missing details! Story descriptions now copy over when duplicating a Story within an iteration just like they should.
- When you create a new Space, it now defaults to the last workflow you visited, so you’re always starting where it makes sense.
- You can now shift-click to select multiple Stories in Table View, because who has time for one-by-one?
- Fixed a bug where duplicating a Story didn’t copy over the description, now it works like a charm.
- Story dialogs just got a speed boost. Now when you open a Story, background loading pauses to keep things smooth and snappy.
Managing complex projects means keeping track of how work connects and sometimes, that’s easier said than done. That's why we added better dependency visualization in Shortcut. Our new Mermaid chart maps dependencies in your Epic or Iteration, making it easy to spot Stories that are blocking or blocked instantly so your team can keep work moving smoothly.
Improvements and Fixes
- Corrected an issue that caused Team (not any of) filter on Stories page to show unexpected results

When you create a Story via the Slack action and select a Workflow, you'll see its available Workflow States to choose from. The default selection is the Workflow’s default state, making it faster and easier to create stories in the right place.
Improvements and Bug Fixes
- WIP limits now stay hidden when using the "Team is not any of" filter to keep your board neat and tidy.
- Importing from CSV now correctly auto-populates with the tool you’re coming from in the Talk to Us modal for a smoother process.

We added Objectives as a grouping option in table view on the Stories page - goals deserve the spotlight too.
Improvements and Fixes
- QuickSearch now keeps your query after closing a search session, because sometimes you just need to pick up where you left off.
- Adjusted the default team icon in the WIP Limits dropdown for proper fit.

You can now resize the main navigation bar to view full titles, making it easier to stay on top of the work you're checking out.

Get instant clarity on your workload with Story counts and Points now visible in the Kanban view.
Improvements and Fixes
- Our tables just got a refresh! You’ll notice a more compact style for easier scanning, updated header groupings and adjusted column widths for improved readability, consistent button sizing within table cells, and polished empty states across the board.
- Emoji shortcodes in URLs are now properly ignored.
- Corrected an issue on the invite new users screen that caused radio button content to not display.
- Fixed a bug in the Story dialogue drop-down UI that prevented the top-most items from being visible.
- Added a fix so newly created Objectives now appear immediately.

We've upgraded our emoji support in Shortcut, so you can now access tons of new emojis to add your favorite flair and reactions to your Stories and comments! Some of the new emojis include: 🧋🦖🤝
Improvements and Fixes
- Corrected the placeholder text in filter dropdown search bars
- Fixed a bug with filtering on Roadmap table view
Get more done with the new Stories page! Watch the video to see how managing your Spaces on the new page is simpler, and built for your workflows.
Read more about it in our Help Center article →
Improvements and Fixes
- To keep week-of-year calculations consistent, we've updated our iteration automation to use the ISO-8601 definition
- If a Story is marked as done, the due date shown on Table View is no longer red
- Corrected an issue with sub-header backgrounds on Dark Mode
- Fixed a UI issue with gray background showing in red WIP limit columns
More space to plan and share your product strategy: Teams can now add up to 100 Epics for each Roadmap 🗺️
Improvements and Fixes
- Corrected a bug on the new Stories page with week headers
- When a user changes the filters on the Stories page, 'group by' is no longer reset
- We corrected an issue on the Reports page where nested dropdowns would close too quickly
Filter to Stories that were completed in the last day, week, month, 6 months on the new Stories page to quickly see what your team accomplished.

New Ways to Share and Reference Your Work
- Quickly Copy Branch Names: You can now easily copy branch names directly from the Pull/Merge Request dropdown in the Story Dialog.
- Epic Permalinks: Epics now have permalinks! Quickly copy a permalink for any Epic with a single click.
Improvements and Fixes
- Added team's colors to the WIP Limits Team Select component
- Corrected a WIP Limits UX bug
- Improved the loading pattern when you open a Story Dialog
- Kanban View now matches Table View by showing Story Count, Story Points, and Completed Points in grouped headers for a clearer overview.
- You can now access the "Move to Top" option in Story Actions when opening a Story via URL.
- Changes on the Roadmap page now reflect faster without needing a page refresh.

Pinned items are now located in your main navigation, making them easier to find and faster to access.
Improvements and Fixes
- The "Beta" badge is gone from the new Stories page, and we've added a "Legacy" badge to the old one as we prepare to transition everyone to the new experience soon.
- Fixed an issue where an Epic toast message showed up twice when converting a Story to an Epic.
- Hitting
enterin a WIP Limit field no longer clears all the values. - Fixed a bug causing workflow state columns to flash white in dark mode.
- Resolved an issue affecting Roadmap exports.
- Addressed a UI regression in table view on the Stories page.
- Fixed CMD+Click in Table view to open Stories in new tab as expected.
- Stories accessed through URL links (like in Slack or email) can now be moved to the top of their Workflow State column using Story Actions.

The faster Stories Page experience just got faster
We’ve upgraded the scrolling and pagination experience on the Stories Page, making it smoother, faster, and ready for more action. Now, you can load up to 12x more items on the first load while maintaining lightning-fast load speeds and seamlessly scroll through 5,000 stories per column.

Also new on the Stories Page - you can now right-click on a Story on the Kanban view and select "Move to Top" or "Move to Bottom" of a column, making it easier than ever to organize your work.
Improvements and Fixes
- Easily see when work was completed - the Completed column on the Stories Page now includes week groupings.
- Fixed an error affecting Epic creation.
- Updated the story type and iteration dropdowns to ensure icon colors display correctly in create and view story modes.

New: Work in Progress (WIP) Limits
Keep your team on track and spot bottlenecks early with suggested limits for Stories in development. Set up your WIP Limits via your Settings in Shortcut. Read the Help Center article for more details or watch our walkthrough.
Improvements and Fixes
- Resolved an issue in the Markdown editor where the Copy and Wrap buttons could be cut off at the bottom when a code block has no line after it
- Doc Relationships no longer flicker when opening a Story Dialog
- Fixed caching issues on the legacy Stories page that caused some users' views to become outdated. 🚀 Check out the new Stories page for even faster load times!
- Corrected a bug that prevented Iteration deletion
- Copying text into Story descriptions in Safari now works correctly
- Titles now wrap properly on Story cards

Keep your Stories aligned with Pull Requests! Using our VCS integration, you can now create a Story directly from a pull request by adding the comment [sc-new-story] on the PR.
Improvements and Fixes
- Observers can now view Shared Spaces on the Stories page by adding them to their tab list or accessing them through a shared link.
- Fixed a bug in the Integration modal where the Delete button was pushed off-screen.

Detail pages for Iterations, Epics and Teams now have collapsible sidebars, giving you more space to focus on your work, while keeping key information at your fingertips. Use the keyboard shortcut m for quick access.
Improvements and Fixes
- We've updated the 404 page for workspaces where the Docs feature is turned off.
- The error message for reaching the Key Result limit per Objective now explains why we cap Key Results and recommends keeping 2-5 KRs per Objective for better focus and impact.
- Google Drive files now display upon attachment without the need for a browser refresh.
- Improved performance in filter drop downs on the new Stories Page.

See only what you need: Visit the Features page in your Settings to toggle on/off Docs, Objectives and Iterations. If you do product documentation or track Objectives outside of Shortcut, simply toggle those features off and keep your source of truth where it belongs.
Work-in-Progress Limits Early Access Program
Work in Progress Limits is now available to Orgs with Early Access. Enable WIP Limits for any Team-Scoped Space on the new Stories Page for your team to help reduce context switching, identify bottlenecks, and improve focus by setting a suggested limit on Stories in progress. Learn more about the feature here. Want Early Access to WIP Limits? Fill out this form.
Improvements and Fixes
- Updated the confirmation modal UI when closing an unsaved Space on the new Stories Page
- Column title on the Status page no longer goes into neighboring columns
- Copy/pasting text followed by a URL now works correctly
- Corrected bug that popped up when tab switching with
Ctrl+Tab

- The UX copy in the New Stories Page tabbed menu for Spaces now says "Save" instead of "Publish," aligning with the save option used elsewhere.
- Teams can now add up to 20 Key Results to each Strategic Objective—more room to measure and celebrate all your wins!
- Shared Space URLs for a Space on the old Stories page now redirect to the same Space on the new Stories page.

Clearly see your project’s progress with our new Roadmap enhancement! Instead of hovering over each epic, you can now see more of the contextual health status updates at a glance, making it easier to stay on top of things and keep everyone in the loop.
If you don’t see this column in your Roadmap, you can easily add it via the Display toggle. It’s a simple way to give anyone looking at the Roadmap a quick update on where things stand and if anything needs attention!
Improvements and Bug Fixes

- Improved UI for workflow state name and metrics visibility in Kanban column headers on the New Stories page.
- For easier Epic creation, the 'Create' button on the Roadmap page navigation now creates a new Epic.
- Fixed a UI bug on the Objective page where the search box retained text from the previous Epic search.
- Resolved an issue with the print layout for Docs to ensure proper formatting.
- Fixed the image navigation within a story so it now correctly navigates between images.
- If a request to create a new iteration fails, the 'Create Iteration' button now correctly resets to its original state.
- Using our CSV Importer, you can now import an external link that's associated with a Story, such as a Helpdesk ticket URL, Slack thread URL or any other external link.
- Stories imported with a
completed_atdate will now retain their original completion dates when imported using the CSV importer.

Improvements and Fixes
- Updated pagination on Objective Detail Pages so you can now scroll seamlessly without having to click "Load More"
- Fixed a bug where columns were not hidden when applying workflow state filters
✨ You can now save changes to your Space using shift + s
Improvements and Fixes
- Corrected a bug with the sort comments button in the Story Dialogue
- Added a tooltip to explain when your team's roadmap has reached the maximum number of epics
- Fixed an alignment issue with the date marker on the Roadmap Timeline
- Added Move to Next Iteration in the context menu on the new Stories page for quick access
- Fixed a Story Dialogue comment button bug
- Corrected an issue with the Spaces tooltip
The latest changes to the new Stories page help you better manage Spaces. Your new Space menu drop-down is now in tabs where you'll see familiar options, like edit to change Spaces names. Publish unsaved changes so your team can see the same view and quickly see who owns each Shared Space in your tab list!
We've improved search with a new is:backlog operator, making it easier to find Stories in your backlog instantly.
Improvements and Fixes

- On the new Stories page, see the
and, orto help distinguish between the two filter groups available. - Copy code blocks with a single click! Simply hover over a code block and click the Copy button.
- Cleaned up the UI for the Space Tab Menu
- Added a fix to iteration automation behavior for UTC
The latest changes to the new Stories page help you better manage Spaces. Your new Space menu drop-down is now in tabs where you'll see familiar options, like edit to change Spaces names. Publish unsaved changes so your team can see the same view and quickly see who owns each Shared Space in your tab list!
We've improved search with a new is:backlog operator, making it easier to find Stories in your backlog instantly.
Improvements and Bug Fixes
⭐ ️On the new Stories page, see the and, or to help distinguish between the two filter groups available.
⭐️ Copy code blocks with a single click! Simply hover over a code block and click the Copy button.
⭐️ Cleaned up the UI for the Space Tab Menu
🐞 Added a fix to iteration automation behavior for UTC
- Fixed a bug affecting creating a new Epic from the Story Dialogue Epic
- Corrected the Roadmap Export PNG Image to properly capture the entire Roadmap
- Corrected a UI issue with Epic input fields
- Addressed an error that popped up when a new Workflow was created
- Docs section now expands after adding a Doc
- Fixed a bug with bulk select to remove Stories that have been filtered out
You can now quickly show/hide filters on the new Stories Page without removing them from your filter list. Easily run your team stand-ups by selecting/de-selecting owner filters and if you want your teammates to see the same view, save the filter state to your Space.

Community Slack Channel
- The Shortcut Community is now on Slack! Connect with other Shortcut users, the Shortcut team, and share what your team is working on.
Improvements and Fixes
- Fixed a bug with URLs containing Shortcut usernames
To help you work faster, we added more keyboard shortcuts for the Story Dialogue:
shift+Ito set the iterationshift+sto set stateshift+eto set estimatecmd+shift+,to copy branch namecmd+shift+.to copy branch name and move into development
Improvements and Bug Fixes
- Fixed a UI issue with the Jira Importer
- Corrected a UI issue with the Swimlanes view on the Status Page and the iteration filter now also works correctly
- Story states are no longer updated based on PR label activity after completed/deployed
- Updated a broken link in the CSV Export email
⭐ ️On the new Stories page, see the and, or to help distinguish between the two filter groups available.
⭐️ Copy code blocks with a single click! Simply hover over a code block and click the Copy button.
⭐️ Cleaned up the UI for the Space Tab Menu
🐞 Added a fix to iteration automation behavior for UTC
Introducing a NEW Stories Page, now available for new Shortcut workspaces

Built to make your daily tasks, iterations and work triaging simpler:
- Speeds up to 10X faster
- Instant interaction with story modals that render over the Stories page
- Manage your list of Spaces using tabs at the top of your Stories page
- A drastically improved filter experience
- Edit all of your personal spaces, even "pre-made" spaces from Shortcut
The new Stories Page is now available for new Shortcut workspaces. Existing teams can still use the beta toggle to opt in to the new Stories page. We'll provide a timeline soon for when everyone will transition to the new Stories Page.
Improvements and Fixes
- The new Swimlanes view on the Status Page now properly filters out other team's Stories, so you can effectively run your standups using only team-owned Stories!
- Added a No Iteration option in the Status Page Iteration Filter
- Fixed a UI bug for color picker select options on the label page
- Fixed an issue to now properly store feedback form drafts when you give us feedback via the in-app form!

The Status Page just got an upgrade! You can now check up on work-in-progress by each teammate with Story Owner Swimlanes and run team stand-ups within the Status Page. Soon, you'll also find Swimlanes on the new Stories Page.
Other improvements and bug fixed from this week include...
🐞 Backlog workflow states now correctly show on the Status
Page
What's New on the New Stories Page Beta
- You can now click and drag to horizontal scroll on the new Stories Page so it’s easier to navigate
- The filter type drop-down length has been extended to make it easier to see more options and search within it for added ease
- We’ve brought all our keyboard shortcuts to the new Stories Page to help you work faster
- Improved UI for accessing links to personal Spaces that aren’t shared
- The filtering experience on the new Stories Page has been updated for mobile users
- The Demo Workspace now uses the new Stories Page
We'll provide a timeline soon for when we plan to complete the Beta and fully migrate to the new Stories Page.
Improvements and Fixes
- Fixed a UI issue with workflow states from different workflows and groupings within tableview
- Corrected an issue with the Google Sheets integration so it no longer becomes disabled when encountering an error
- When creating a Story in-line on the new Stories Page, that team’s iteration is now selected for that Story
Spaces are now more discoverable on the new Stories page with an updated Space Menu UI.
Improvements and Fixes
- Fixed a Google Sheet integration error
- Fixed a UI bug for adding a story in-line within Kanban columns
- Requestor is now available as a column that you can enable on the Stories page and backlog table!
- When you convert a task into a Story, the task details are automatically added into the new Story's description, it's marked as complete, and the new Story is linked to that task
- More color options are now available for labels
- Expand and collapse Story comment threads in the story dialogue

Improvements and Fixes
- The search relevancy when you mention a teammate in Shortcut has been improved! Now, when you start typing a teammate's name, the most relevant names surface to the top of the list
- Fixed the padding for story comments and comment threads
- Eliminated a bug on the new Stories Page that popped up when loading more in table view
- Corrected a UI issue seen when dragging Stories into an empty column
- Corrected an error with cycle time reports
Moving data into Shortcut via CSV Import just got easier! Now, story types (string values feature, bug, and chore) are imported via CSV Import, and id is no longer a required field.
Improvements and Fixes
- Team icons now display correctly in dark mode on the new Stories page.

Estimate delivery accurately with Cycle Time
The Iteration Cycle Time Chart has been rebuilt for improved data accuracy and UX. Track the time it takes to complete stories and use data-driven insights to get a solid grasp of your team's processes.
Bulk-edit Stories on the New Stories Page
We've brought back the ☑️ at the top of each workflow state column to enable bulk-edit. Managing your Stories just got snappier on the New Stories Page!
Improvements and Fixes
- Enhanced our Github integration to show PR build status for GitHub Actions on the Story pane
- Fixed a bug that popped up in comment states when navigating between stories
- Team names on the Epic dialogue are now ordered alphabetically
- Corrected a tooltip bug on the New Stories Page
- Fixed login behavior to direct users to the workspace dashboard if logging in with no active Workspace association
Deleted user profiles can no longer be assigned as the owner of a Story via a GitHub integration action.

✨ Sync Slack threads to Story comments (and vice versa!) so teams don't lose important context or conversations. Check out the demo video.
👉 Contact your workspace admin to re-authorize your Slack integration to access this update.
View Epic Health on Epic Table View
Sort and organize Epics by health status or easily find Epics that don't have a health status.
Improvements and Fixes
- Fixed bug where reporting charts do not generate data with Advanced Custom Field filter when no value filter is selected
- Corrected an error that popped up when assigning an Epic to a Story with no Team assignment
Share your in progress and upcoming work! You can now export your Spaces with the most up-to-date filters as a CSV file by clicking "Export" in the drop-down menu.

✨ New Integrations: Embed Loom and YouTube videos in Stories and Comments
Explain complex ideas and provide feedback with pre-recorded videos. Paste any Loom or YouTube public link into Shortcut's Markdown editor and the link turns into an embedded video so you can automatically play it in the description field, comment or Docs.
Improvements and Fixes
- Fixed an issue where deleted comments were impacting the comment order
- Added mobile UX improvements to the Text Editor
- GraphQL comments in Docs code blocks no longer remove formatting
- Tasks and Story Relationships now persist in Story drafts after a refresh
- Added a fix for a story dialogue bug to speed up loading updates
- In Table View on the new Stories page, when you group by Iteration, the order is now descending to help teams with their planning workflow
- On the new Stories page, Epic Filter is now scoped to Team on Team Scope Stories Pages
- Fixed a bug with Space Save As on the new Stories Page

We continue to improve the text editor experience to create a better way for you to collaborate with your team. Add tables, diagrams, and quickly format comments using keyboard shortcuts or the updated Editor toolbar with more one-click formatting options. Any pre-formatted text you paste will retain its formatting - even links! - to ensure consistency and let you move faster.
✨ When you group by in tables, none is now at the bottom of the list of groups so you can view your highest priorities first.
Improvements and Fixes
- Automations are now attributed in Shortcut history!
- On the new Stories page, filtering on
not any ofworkflow states completely hides columns that are filtered out - Addressed drag and drop bug on the new Stories Page
.gif)
Table View on the New Stories Page Beta
View your Spaces in Table View and save that view setting to your Space! Also, save your Group By setting, as well as sort by and show/hide values.
Quickly Add a Story in Kanban Columns
Create a story in context of any workflow state column via the "+" or "Add a Story" in empty columns.
Create a new Story with Shortcut.new
You can now type shortcut.new into any browser and we'll send you right to the Create a Story dialog, as long as you're logged into your Shortcut account.
Improvements and Fixes
- Ordering of Workflows in CFD Report tooltip now matches the order of the chart (Unstarted > Done)
- Added a fix to the Velocity Chart so it now correctly matches the data in the Completed Stories table

We've added support for Mermaid in Markdown in Shortcut! Mermaid makes it easy to create and render detailed diagrams and charts, like flow charts, Gantt timelines, architectural mapping and more.
Get started by adding ```mermaid on the opening line of a code block directly inside description areas in Shortcut.
🆕 Epic health now displays on the Epic tooltip for easy readability of important details on hover.
Improvements and Bug Fixes
- Archived Objectives are no longer displayed in the dropdown when assigning an Objective to an Epic
- Emojis will now properly render in Titles in the Markdown editor
- Hitting the
esckey will no longer close the Story modal when viewing an image attached to the Story - The Story name will properly wrap on the warning modal when deleting/archiving

Easily share your team's Curated Roadmap using the new Export to PNG option
- Share a view of what's on the horizon and in progress for each team's Curated Roadmap with a click of a button
- Preview the export and download or copy to your clipboard to easily paste into other products such as Slack or a presentation
- What's on the page will be exported based on filters applied to make the view even further personalized prior to export
🆕 Markdown Experience
We continue to improve the markdown experience for everyone. We've added some options for link handling so when you're pasting links, you now get the choice to leave it as-is, or apply the Markdown using the Create Link option.

You can also now use the sum function in tables for columns and rows to help with basic math commands. The updated Markdown experience is now applied to Iteration and the Epic detail page description areas!
🌟 New Stories Page Beta
We're wrapping up our work on the new Stories page and shipping updates regularly. New this week: you can now Filter on Stories created and updated in the last 6 months, as well as Stories with Epic Labels. We also deployed a few fixes:
- Load more stories in
doneworkflow states that are >30 days since updated - If you move a story into
startedworkflow states, the story updates with you as the owner - Fixed a bug where a space was incorrectly showing no results
Also new this week:
- Backlog enhancement: Filter for
Requestersso you can filter the Backlog by who requested each story ✨ - Roadmap update: More actions have been added to the right-click context menu for easy Roadmap management, including: Move to top, Move to Bottom, Archive Epic, Delete Epic, and Copy the Epic link.
Improvements and Bug Fixes
- Use
ShiftorCMD/CTRL+ Right-click on a pinned Doc now works as expected - Objective Key Results no longer require a double-click to collapse upon first page load
- Emojis now properly render in Epic Titles/Descriptions consistently across Shortcut
Load Moreon the Backlog will no longer fail to load stories and cause blank Story rows to appear- Editing the description of one Story will no longer cause the description of another Story to stay in edit mode when navigating between Stories
xcan now be used within Markdown checkdown brackets to mark as done

Get context on planning progress with Objective health updates
Numbers only tell part of the story around whether work and goals are on track, at risk, or off track. Now teams can streamline tracking and add a health status and comment alongside Key Result updates. Let stakeholders and teams know exactly what's happening on Objectives in Shortcut in detail.
- Health status and comments can be added directly on the detail page or from the Objective tableview to keep track of changes over time to how your goals are going.
- The latest Health status and comments are displayed on the tableview and the health status on the column view to easily identify the state of an Objective.
- Filter and group by Health to easily identify blockers, discuss what's at-risk and make plans to move work forward.

Easily link and review planning documents from your Objective's sidebar
- Easily find and review important planning docs by adding them using the View Doc or Copy to keep important docs readily available for deep dives.
- Quick and easy Doc management with options to Archive and Delete Docs no longer needed quickly using the context menu
- Save important docs for later using the Pin option from the context menu to keep the most important planning and goal docs available in your pinned menu.
Improvements and Bug Fixes
- 📧 Get notified by email if your workspaces' GitLab integration is misconfigured/in an invalid state
- Roadmap progress bars in the table view no longer get cut off by the drag-and-drop handle on side-scroll
- Epics on the Objective Detail page will now show all assigned teams if the Epic is assigned to multiple teams, not just the first
- Selecting a new workflow from the workflow dropdown for stories in the Backlog will now properly update the workflow if changed
- Quick follow improvements for text editor on the Stories Dialog:
- Line breaks are properly handled and respect Markdown formatting around them
- Unfurls for Figma/Embeds properly show instead of turning into a Markdown "Link"
- The description area is now expanded after saving
- Markdown Tips now appear alongside the Story Dialog instead of behind it
- New Stories Page Beta:
- Resolved an error when clicking the back button
- Cleaned-up Story behavior when the workflow state filter changes on a Space

It's now more efficient to collaborate on content directly in Stories with improved formatting options. Highlights include:
- New Keyboard shortcuts for popular markdown actions to quickly add formatting, such as cmd+b / ctrl+b to bold
- Already formatted content can be pasted in and all formatting will be maintained. For example, if content is already bolded, we will auto-apply the markdown to keep the bold format!
- A new look and feel for the Editor toolbar with more one-click options to add desired formatting. You can also continue to manually type in markdown formatting if you prefer!
- Many UX improvements such as auto-applied placeholder text when pasting in links to make links cleaner, and 1-click table formatting for easy table building
🆕 Epics: You can now duplicate Epics via the Epics tableview and Epic Detail Page actions menu.
Backlog: Filter by Requester has been added to filter by all stories specific people have created.
Improvements and Bug Fixes
New Stories Page Beta
- Navigating within the Stories page workflow state columns no longer causes Stories to shift across columns
- Navigation "back" no longer causes a bug rendering the stories page
- Previously rendered stories no longer show up on a Space when switching between workflows
It's now easier for teams to move from Pivotal Tracker to Shortcut! Our new MIT-licensed open source import tool leverages our API to streamline the process of getting your data into Shortcut. Learn more in our Help Center article.
Load More on the Backlog page: Prioritize and manage Stories without the limitation of pagination 🙌
Bug Fixes and Improvements
During our Bug Bash we deployed 176 improvements, fixing bug fixes, addressing UI inconsistencies and removing paper cuts.
- Search Operator suggestions now scroll once show more is clicked
- Linking to a Story in a workspace a user doesn't have access to will now show a 404
- Dragging a file onto the Story Dialog now works correctly
- UI improvement for
Add Epicto a roadmap - The
'epic:'search operator now shows suggestions - an alphabetical list of available teams and a "show more" button - Profile photos now upload correctly
- Added a link to Shortcut status page from the Profile menu
- UI improvements for Help in Shortcut
- When creating a new epic from an empty Objective, the Objective is no longer listed twice
- Fixed UI bug with Objectives badges
- Removed Observers from Owner dropdown on Reports page as they are not interactive members
- Deployed improvements for new text editor experience on the Story dialog
- Corrected a routing issue when navigating twice to create workflow as non-admin
- Filter dropdowns are no longer showing up on top of Quick Search
- The drag-to-resize-sidebar control for the Docs sidebar is no longer over the minimize button
- Keyboard navigation improvements for search operator results
- Implemented UI improvements for Search
- Fixed an issue with Notion link previews
New Stories Page Updates
- Fixed an issue that caused stories in workflow state columns to consistently shift
- Corrected an issue with Avatar colors mis-aligning with the Avatar colors on the original Stories page
- Addressed an error that occasionally popped up when closing/deleting a space in the tab list
- Filter UI improvements
Over the past two weeks we've been diving into quality improvements, like fixing bugs and removing paper cuts. With just a couple of days left in our bug bash, we've already made 138 improvements, including:
- UI fix for setting up custom fields on mobile and you can now access the settings menu
- Teams moving to Shortcut can now better import their data with Story type mapping
- Table headers are now sticky on Safari
- Expanding/collapsing the collections page no longer changes where you're scrolled to
- A quick fix to help teams move from JIRA! Increased the width of the input fields on our Jira importer so you can better see what you're typing
- Users can now use the prev/next buttons on the search page
- When creating a team, the name field now auto-populates the team Mention Name
- Health is no longer hidden behind the text area when you're adding a comment to your status update
- When a Story is converted to an Epic, it no longer loses its Team association
- On the Home page, the My Stories column now shows all Stories that a user owns
- On the Iteration detail page, the right next arrow now functions properly
- Removed "new" badge from Workspace Features > Automations
- Slack integration now properly formats markdown URL reference style links
- Added a fix on label chips, so g's are no longer being cut off
- When a column is collapsed the workflow states headings are now one line
- Clicking
EditonCustom Fieldswhile editing a Story Template now goes to the custom fields setting page - Keyboard shortcut for "n" now correctly opens a new story modal
- The
'team:'search operator now shows suggestions - an alphabetical list of available teams and a "show more" button - Dark mode enhancement for table headers in detail pages
- UX enhancement to clarify that when creating a team you have to select a workflow to continue
- Fixed an issue when updating to a team so the user is now prompted to select the workflow the story should go into and then the target workflow state
- The first item of a team's context (right-click) menu is now aligned correctly
- Added Space to the top of the calendar range picker so iterations no longer look like they're cut off
- Fixed a UX bug so the file attachment overlay is no longer truncated in some cases
- Improved the Create Story menu to add template headings in Create Story sub menu
- Advanced search UX improvements to reduce input size and make operators full-width
- Accessing
/settings/teamsdirectly without a workspace now redirects to the teams page of the default workspace - Menu options now filter accurately relative to the keywords entered
- When creating a team using a name that already exists an error now lets you know it's a duplicate name
- If a user turns a task into a Story, the Epic and the Iteration from the initial story are now carried-over
- When navigating to settings directly from the Reports page, the loading illustration now displays on top of settings page content
- External links are now updated correctly when using the Update Multiple Stories API Endpoint
- Slack Create a Story action: now allows you to search for Iterations and select one for the newly created story to be assigned to
- When converting a Story to an Epic, the originating Story Tasks now get the same team assignment that the original Story had
- You can now Create a Story from the Epic and Iteration detail page Stories section
- Print Dialog now includes all the information on the Epic detail page
- Mobile UX enhancement Update Automation sub-headings fit better on screen
- Corrected a mobile issue with our billing notification email template
- Mobile UX improvement for new user invites
- Mobile UX improvement: so custom fields with long names now correctly wrap
- Mobile UX improvements for Settings pages
- Mobile UX improvements for Story Dialogue footer
- Fixed an issue on the Dashboard so the My Stories column scroll does not reset to the top of the column when switching tabs
- Corrected a bug with infinite loading in the story dialog
- If “Create Another” is selected in the Story dialogue the focus returns to
Story Titleso that you can create another Story quickly
New Stories Page Improvements
- Backend speed improvement for Stories 2.0 page tab list and Spaces
- Several Stories were deployed as part of Table View development 🙌
- Add borders to inactive tabs
- Backend change for memory bandwidth improvements
- When more stories load in a kanban column, the stories that you see stay fixed instead of shifting upwards
- The actions at the right of column headers are now aligned with the Story Cards in the column
- Changed the keyword filter name to
searchto better describe what it does - Investigated and fixed a bug with odd shifting behavior when loading Kanban columns
- When an unsaved space is saved as a shared space, the space name and permission is now correctly updated
- The dropdown for filter selection is automatically opened when a user selects a filter type (pill) to speed up setting filters on a Space!
- Fixed an issue on Safari so you can now see the Story card as you're dragging between columns/positions
- Added a UX fix by increasing the max width of our drop-down selectors for filters to help make long titles more legible!
- Stories are no longer missing from a tab when scrolling horizontally and then switching to an uncached tab
- In Team Scope Stories pages, if a user clicks create space and then closes the space without changing it, the space is automatically removed from your Space tab list and menu
- Quickly resolved a reported UX bug so empty collapsed columns no longer have scrollbars on hover in kanban view
- Corrected capitalization of Story Type in Filter Selector
- Tooltip for "undo changes" no longer shows up behind the Save/Edit Space menu dropdown component
- Updated the tooltip for "Add a Story" feature that is coming soon to the new page!
Add multiple teams directly to Epics to show multi-team ownership.
Improvements and Fixes
- New Stories Page Beta Quick Follows:
- Matches All/Matches Any filter groups enable an "or" conditional
- Removed an erroneous empty state error
- Added a fix to ensure backlog workflow states are in the right position in kanban view
- Clicking a link to a story comment reloads the Stories page in the background
- Coming Soon: "Add A Story" in Kanban columns!
- Today we're kicking off our Bug Bash, dedicating the next two weeks to fixing bugs and removing paper cuts.

Iteration Insights: Hit your Iteration goals with new at-a-glance versions of your Burndown and Cumulative Flow reports to quickly understand how work is progressing, identify bottlenecks in the process, and determine if you'll meet your commitments.
.avif)
Breadcrumbs show you which Objectives your Stories and Epics trace back to for easy discoverability, navigation and seeing how work connects to strategic outcomes.
Improvements and Fixes
- Search field for Objectives on the Report page now properly returns results
- Add Epics option under Key Results now only displays when there are Epics to add more
New Stories Page Beta Quick Follows:
- Added the ability to filter your Spaces by Project
- Fixed a caching bug related to drag and drop
- Solved an issue with 'Save As' in the Save drop-down menu
- Fixed a bug with drag and drop in Safari
- Visiting a Story comment link no longer causes an error

✨ Introducing the all-new Stories Page beta. It unlocks:
- Speeds that surge ahead by up to 10X
- Instant time to interact with story modals that render over the Stories page
- Manage your list of Spaces using tabs at the top of your Stories page
- A drastically improved filter experience
- Edit all of your personal spaces, even "pre-made" spaces from Shortcut
👉 Opt into the new Stories page beta via the switch at the top of your Stories page.
We are releasing more functionality and improvements on the new Stories Page regularly! Quick-follow improvements include:
- Search for custom field values
- Search for filter types
- Fixed a bug affecting paging between Stories
- Squashed a bug with enabling attachments to Stories
🗓️ Register now for our new Stories page webinar on March 26th. The team will cover what to expect from this fully redesigned page, what improvements come with it and what it means for the future of Shortcut.
Backlog
- Enable new columns on the Backlog Page, including: Labels, Created On, and Last Updated
- The "More Actions" dot menu is now available per story, allowing easy opening of the story, pinning, link copying and archiving
Improvements and Fixes
- Focus is returned to the story title dialogue after setting 'create another'
- Objectives: Key Results now expand by default to see the Epics assigned for easy discoverability
Update Objectives Key Results values through our 🔗API programmatically.
Pick up your next Story quicker - the Docs section on Epic and Iteration pages is now closed by default.
Improvements and Fixes
- Docs: Fixed a bug where comments where hidden if left near the bottom of a Doc. 🙌
- Reports: Clicking the legend of a Report now scrolls you back to the top of the page.
- Objectives: Objectives with start and end dates will now appear on the Roadmap even if the Epics within them don’t have dates.
- Epics: Epic Detail Pages no longer trigger dropdown edit, but properly trigger a new tab being opened when cmd+clicking on the View Objective Page option.
- Epic Health: When Epic health is updated, the email sent now clearly states that the email contains a new Health Update in the subject line.

Help, Now Powered by AI ✨ Goodbye to searching through long docs for answers, hello 👋 TL;DRs! Get quick, concise answers to your Shortcut questions with the power of AI.
Back by popular demand 👏 We've brought back the summarized tooltip on the new Iteration Cumulative Flow Diagram Report, so you can see the totals of all workflow states at once.
.gif)
- Navigate to Reports from an Objective Detail Page, auto-filtered to that Objective for easy reporting 📈
👉 Register for our Objectives Webinar on Tuesday, March 5th, 2pm ET/11am PT for a discussion all about Objectives, including best practices, tips for writing effective OKRs and how it's changed the way we work at Shortcut.
Improvements and Fixes
- Added a fix to the Light Mode Selector UI for Requestor Drop-Down in Story Modals
- Fixed the Upgrade flow from the Create Team modal by removing a blank toast modal
- Made Epics show their status and last updated on the Epic row in the Objective Detail Page
- Added a loading animation to the Roadmap to make it more clear that the page is loading

✅ Keep everyone informed on status by updating Epic Health directly from the Objective Detail Page
🙌 Key Result values can now be <0 and >100 to represent values of all kinds
🎯 Decimals are now supported in Key Result updates and you can edit the start value of a Key Result
Improvements and Fixes
- Fixed a bug so the Objectives filter on the Column View now appropriately filters the Epics related to the selected Objectives
- Corrected an issue so filtering by Objectives now correctly provides the right data back, showing all respective Objectives
- 🔗 Links in Objective descriptions now work properly and link you out to the URL when added via Markdown
- Don’t worry about story templates created/owned by teammates who left your workspace - they’ll work as expected without any error messages!
🎯 Connect Work <> Company Goals with Objectives
Create goals, align teams, and connect individual projects to company objectives. Now, not only can you roll up work across multiple teams in a tactical way using Objectives, but you can begin to track outcomes and impact using key results.

Get more information about Objectives with these resources:
- Check out our help documentation
- Visit our blog post
✨ Jumping from your activity feed to comments just got easier!
Clicking on comment notifications in your activity feed will now link you directly to the comment in the story dialogue.
Improvements and Fixes
- Shipped a fix for the Roadmap Timeline, so it no longer erroneously filters out Epics belonging to multiple Objectives.
- Fixed a bug that caused the detail page to error when an Epic was pulled into a Key Result.

🎯 Introducing Shortcut Objectives, a new way to organize product development work around company goals.
To help you reach your most important goals, we're introducing a seamless way for all teams using Shortcut to be more objectives-focused.
✅ Connect Planning with Execution
Ensure everyone in your organization is aligned with your company goals. Objectives let you define goals, connect them to Epics, and track ongoing progress. They help keep everyone focused and driving towards the right outcomes.
🚀 Drive Results by Keeping Objectives Top of Mind
Managing your goals in the same tool you use to manage your work prevents teams from forgetting the goals you initially set out for them, and ensures they're constantly aware of how their work ties back to each Objective.
🧠 Work Smarter with Real-time Visibility
Get a clear picture of all the Epics that are being worked on for each Objective and how much progress has been made towards each.

💡Two Types of Objectives: Tactical & Strategic
- Tactical Objectives allow you to group and track Epics only. (Use these for day-to-day execution)
- Strategic Objectives allow you to group both Key Results and Epics related to those Key Results. Use these for higher-level planning and OKRs. (Available only on Business & Enterprise plans)
- Note: Milestones are now called Tactical Objectives and can be found on the new Objectives page.
👉 Learn about what's changed
Improvements and Fixes
- Teams on the Teams Page are now sorted in alphabetical order -- now aligned with the same pattern as our dropdown and team navigation. 🙌
- Fixed issue where @ mentions in Docs comments didn't send a notification to the user.

It's even easier to see where your team's bottlenecks are with the new and improved CFD
The Cumulative Flow Diagram (CFD) helps you better understand your team's workflow, increases in scope, cycle time, and throughput! It now has color-coded states, an interactive legend and smart workflow defaults. It's the swiss army knife of charts!
Here's whats new:
- View progress by workflow state: Easily evaluate Unstarted, In Progress and Done work with the new color-coded bands.
- Hover for details: The tooltips for each band reveal their percent of the total and story/point count, as well as the total story/points on that day for all states.
- Choose your View: The workflow with the most stories in the iteration is now the default view or choose other workflows with stories in the iteration.
Learn more about the CFD here!
- Fixed a bug that blocked users from updating their automations
- Addressed an error when users attempt to create a team with the same name with an in app toast message
- Fixed an error that impacted the signup flow experience

✨Temporarily add Teams when opening shared links to Shortcut!
- Click a Shortcut link that's within the scope of a Team that is not in your navigation, the Team is temporarily added to your navigation!
- Add the "temporary" Team to your navigation using our context menu, or click to a different page and the team is removed

We’re redesigning Iteration reports to better convey progress and plan for upcoming work. Our first release is an all-new Burndown Chart!
Here's what's new:
- Track Ideal and Actual Remaining work on a daily basis, as well as stories/points that were Added, Removed or Completed each day via the tooltips
- Ideal Remaining forecasts how many stories/points should be remaining based on time left in the Iteration
- Toggle between Stories and Points with the chart default reflecting workspace setting
- Sync with Latest Data to make sure your chart shows any recent updates to the iteration
Get more information about the new Burndown chart with these resources:
- Check out our Help Documentation
- View our blog post about upcoming Reporting improvements
- Register for our Reporting Webinar on Thursday, January 11th, 2pm ET/11am PT for a look at how our own product and engineering teams use Shortcut to monitor progress and interpret insights!
Improvements and Bug Fixes
- Updated version of markdown in Shortcut to address in-app buggy behavior and cleanup our code under the hood 🙌

Align your teams' work with company objectives
Connect your company objectives with the work that supports them, so teams can prioritize what matters. 👉 Sign up for Early Access to Objectives!
Improvements and Fixes
- The comment icon on the Roadmap Health badge will now only appear if there are actual comments. The count will now properly show only comment counts, not total Health update counts.
- Addressed Custom Fields Setting Page regression
